

Is Forex Signals a Scam? The Truth Behind Forex Signals Exposed
Are Forex Signals Fake or Genuine? Unveiling the Truth When it comes to the world of forex trading, there are countless strategies and tools available …
Read Article

Support Vector Machines (SVM) is a powerful machine learning algorithm that is widely used for classification and regression tasks. It works by finding an optimal hyperplane that separates data points into different classes. SVM is known for its ability to handle high-dimensional data and its robustness to outliers.
One of the main advantages of SVM is its flexibility. It can be used for both linear and non-linear classification tasks by using different types of kernels. The most commonly used kernels are linear, polynomial, radial basis function (RBF), and sigmoid. Each kernel has its own characteristics and can be chosen based on the specific problem at hand.
SVM is particularly useful when the data is not linearly separable. It can handle complex decision boundaries and is capable of capturing non-linear relationships between the features and the target variable. SVM is also known for its ability to handle large datasets efficiently, as it only relies on a subset of the training data called support vectors.
Another advantage of SVM is its ability to handle high-dimensional data. It can effectively handle a large number of features without overfitting, unlike some other machine learning algorithms. This makes SVM a popular choice in many fields, including computer vision, bioinformatics, and text classification.
In conclusion, Support Vector Machines (SVM) is a versatile machine learning algorithm that can be used in a wide range of applications. Whether you are working with linear or non-linear data, SVM offers a powerful tool for classification and regression tasks. Its ability to handle high-dimensional data and its robustness to outliers make it a popular choice among data scientists and machine learning practitioners.
Support Vector Machines (SVM) is a powerful machine learning algorithm that is widely used for classification and regression problems. SVM is a supervised learning algorithm that analyzes the data and finds the best decision boundary that separates the classes or predicts the continuous target variable.
The main idea behind SVM is to find the hyperplane in a higher-dimensional space that best separates the training data into different classes. In simple terms, SVM finds the optimal line or hyperplane that maximizes the margin between the classes. This optimal line or hyperplane is chosen in such a way that it maximally separates the data points from different classes. SVM can handle both linearly separable and non-linearly separable data using different kernel functions.
How does SVM work? Let’s take the case of binary classification. In SVM, each data point is represented as a feature vector in a higher-dimensional space based on its characteristics. The SVM algorithm then maps this data to a higher-dimensional space where it tries to find an optimal hyperplane that separates the two classes with the maximum margin.
The margin is defined as the perpendicular distance from the hyperplane to the nearest data points of each class. SVM aims to maximize this margin, as it believes that a larger margin leads to better generalization and lower error on unseen data.
In case the classes are not perfectly separable, SVM allows for some misclassification by introducing a “soft margin”. The soft margin allows some data points to be misclassified and allows for a more flexible and robust model. The penalty for misclassification is controlled by the regularization parameter, which helps in determining the balance between the margin size and the misclassification error.
SVM can also handle non-linearly separable data, thanks to the kernel trick. The kernel trick allows SVM to transform the data into a higher-dimensional space, where it becomes linearly separable. SVM uses different kernel functions like linear, polynomial, radial basis function (RBF), and sigmoid to map the data into this higher-dimensional space.
In conclusion, SVM is a powerful machine learning algorithm that finds the best decision boundary to separate or predict different classes or regression targets. It works by finding an optimal hyperplane in a higher-dimensional space that maximizes the margin between the classes. SVM can handle linearly separable and non-linearly separable data using different kernel functions, making it a versatile algorithm for various classification and regression tasks.
1. Classification problems:
SVMs are commonly used for binary classification problems, where the goal is to separate data points into two distinct classes. For example, SVMs can be used to classify emails as spam or non-spam, predict whether a customer will churn or not, or identify whether a patient has a disease or not.

2. Text and sentiment analysis:
SVMs are widely used in natural language processing tasks. They can be used for sentiment analysis, where the goal is to determine the sentiment (positive, negative, or neutral) of a given text or review. SVMs can also be used for text categorization, document classification, and text clustering.
3. Image recognition:
Read Also: Calculating Implied Volatility for Nifty Options: A Comprehensive Guide
SVMs are effective in image recognition tasks, such as object detection and face recognition. They can be trained to classify images into different categories, such as identifying if an image contains a car or a person. SVMs have also been used in facial expression recognition and image segmentation.
4. Bioinformatics:
SVMs have found numerous applications in bioinformatics, including protein classification, gene expression analysis, and DNA sequence analysis. SVMs can be used to predict protein function or classify genes based on their expression patterns, aiding in understanding biological processes and diseases.
5. Fraud detection:
SVMs can be used for fraud detection in various domains, such as credit card fraud detection or insurance claim fraud detection. By training an SVM on historical fraud data, it can detect patterns and anomalies in new data and flag potential fraudulent transactions.
6. Handwriting recognition:
SVMs have been successfully used for handwriting recognition, allowing machines to recognize and interpret handwritten text. SVMs can be trained on a dataset of handwritten characters and then used to classify new handwritten input.
7. Recommendation systems:
Read Also: Rp1 000,000 If in Dollar how much?
SVMs can be used in recommendation systems to suggest relevant products or services to users. By analyzing user behavior and preferences, SVMs can predict user preferences and provide personalized recommendations.
8. Time series analysis:
SVMs have been utilized in time series analysis to predict future values or detect patterns in sequential data. SVMs can be applied to financial market forecasting, stock price prediction, weather forecasting, and other time-dependent datasets.

9. Medical diagnosis:
SVMs can assist in medical diagnosis by analyzing patient data, such as symptoms, medical history, and test results. They can be trained to classify patients into different disease categories, assist in the prediction of disease outcomes, or aid in the identification of potential risk factors.
10. Anomaly detection:
SVMs can be used for anomaly detection in various domains, such as network intrusion detection, fraud detection, or equipment failure detection. By training an SVM on normal behavior patterns, it can identify deviations or outliers in new data, allowing for early detection of anomalies.
Overall, SVMs are versatile and can be applied to a wide range of domains and problems. Their ability to handle high-dimensional data, deal with non-linear relationships, and handle binary and multi-class classification tasks makes them a valuable tool in many real-world applications.
A Support Vector Machine (SVM) is a supervised machine learning algorithm that can be used for both classification and regression tasks. It works by finding the best hyperplane that separates the data points in different classes.
Support Vector Machines have several advantages, including the ability to handle high-dimensional data, the ability to handle both linear and non-linear data, and the ability to handle data with a large number of features. They are also less prone to overfitting compared to other algorithms.
You should consider using Support Vector Machines when you have a classification or regression problem and you have a relatively small dataset with a moderate number of features. SVMs also work well when the data is non-linearly separable or when there is noise in the data.
Yes, Support Vector Machines are sensitive to outliers. Outliers can have a significant impact on the position and orientation of the hyperplane, which can lead to poor performance of the algorithm. Preprocessing the data to remove outliers or using robust versions of SVMs can help mitigate the impact of outliers.
Support Vector Machines can handle imbalanced datasets, but they may not perform well if the imbalance is severe. In such cases, techniques like oversampling the minority class, undersampling the majority class, or using class weights can be employed to improve the performance of SVMs.
A Support Vector Machine (SVM) is a supervised machine learning algorithm used for classification and regression tasks. It works by finding the best possible hyperplane in a high-dimensional feature space to separate different classes or predict continuous values.
There are several advantages of using Support Vector Machines (SVMs). First, SVMs are effective in high-dimensional spaces, making them suitable for problems with a large number of features. Second, SVMs often provide good generalization performance, meaning they can accurately classify unseen data. Finally, SVMs can handle non-linear decision boundaries through the use of kernel functions.

Are Forex Signals Fake or Genuine? Unveiling the Truth When it comes to the world of forex trading, there are countless strategies and tools available …
Read Article
How to Calculate the Quarterly Moving Average Trend In the world of data analysis, trends are a powerful tool for understanding patterns and making …
Read Article
Options Account Approval Process: Everything You Need to Know Options trading can be a great way to diversify your investment portfolio and …
Read Article
Calculating the Real Effective Exchange Rate in Ireland The real effective exchange rate (REER) is a crucial indicator that measures the …
Read Article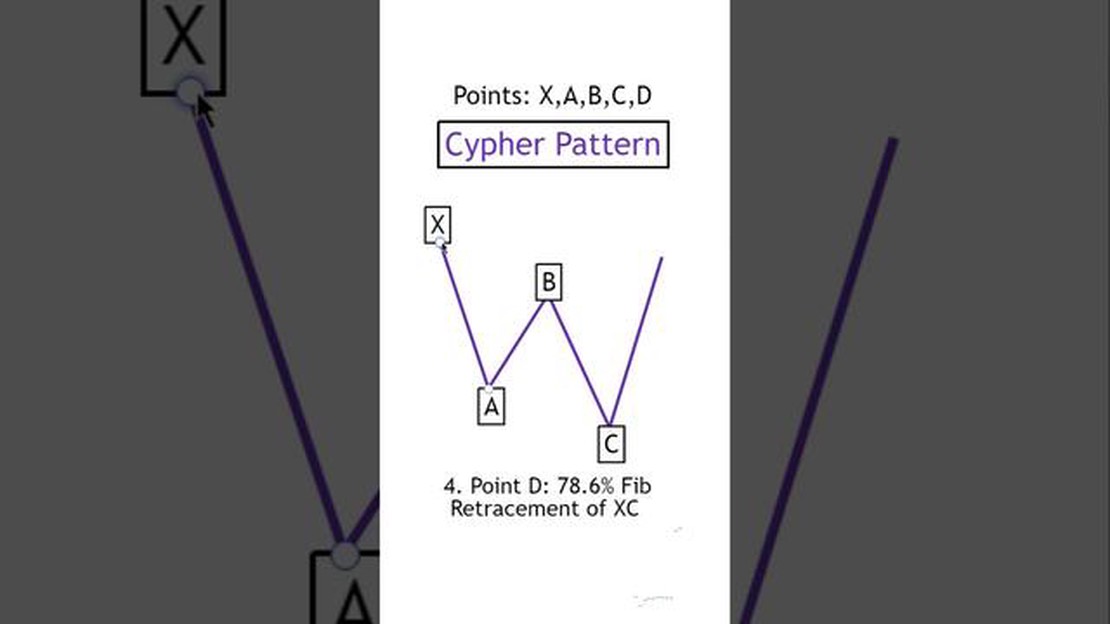
Exploring the Outcome of a Cypher Pattern in Trading When it comes to the world of financial markets, there is no shortage of patterns and indicators …
Read Article
Buyer and Seller Strength Indicator: All You Need to Know In the world of financial markets, understanding the dynamics between buyers and sellers is …
Read Article



