


Learn How to Trade Out of the Money Options | The Ultimate Guide
Best Strategies for Trading Out of the Money Options Out of the money options can be a lucrative way to enhance your trading strategy and potentially …
Read Article
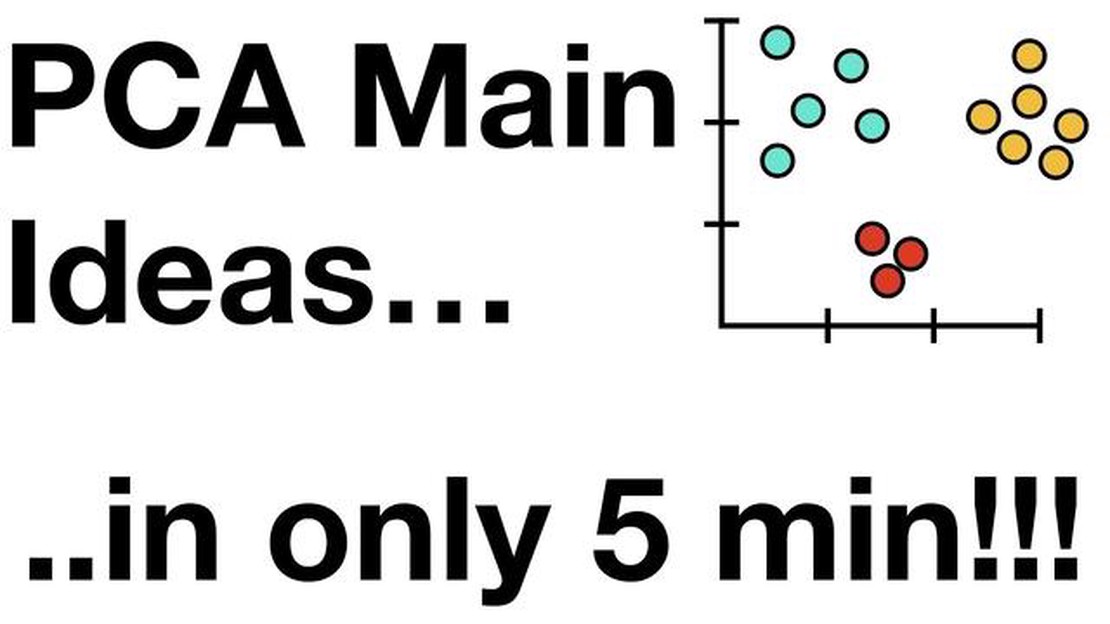
Principal Component Analysis (PCA) is a popular and widely used technique in data analysis and machine learning. It is a mathematical method that transforms a set of variables into a new set of uncorrelated variables called principal components. These components are linear combinations of the original variables and are ordered in such a way that the first component captures the most variance in the data, and each subsequent component captures the remaining variance.
The main goal of PCA is dimensionality reduction, which is particularly useful when dealing with high-dimensional data. By reducing the number of variables, PCA simplifies the analysis and visualization of the data, while still retaining most of the important information. Additionally, PCA allows for identifying the most important features or patterns in the data, providing valuable insights for further analysis.
Understanding the components of PCA is crucial for interpreting the results and making informed decisions. Each principal component represents a linear combination of the original variables. The coefficients of this combination, called loadings, indicate the contribution of each variable to the component. The sign and magnitude of the loadings determine the direction and strength of the relationship between the variables and the component. Moreover, the proportion of variance explained by each component can be used to assess its importance in the overall data structure.
In conclusion, principal components in PCA play a central role in understanding and analyzing high-dimensional data. By capturing the most important information and simplifying the data, PCA provides a powerful tool for data exploration, visualization, and predictive modeling. Moreover, the interpretation of these components is crucial for extracting meaningful insights and making reliable decisions based on the analysis results. Therefore, a thorough understanding of the components is vital for any data scientist or analyst working with PCA.
Principal Component Analysis (PCA) is a dimensionality reduction technique used in machine learning and data analysis. It is primarily used to identify patterns or structure in high-dimensional data by transforming it into a new coordinate system called principal components. The goal of PCA is to reduce the data dimensionality while retaining as much information as possible.
In PCA, the data is represented as a matrix, where each row represents an observation and each column represents a feature or variable. PCA calculates the correlation or covariance matrix of the data and then computes the eigenvectors and eigenvalues of this matrix.
The eigenvectors represent the directions or axes of maximum variance in the data, while the eigenvalues represent the amount of variance explained by each eigenvector. The eigenvectors with the highest eigenvalues are the principal components, which capture the most important patterns or structures in the data.
By projecting the data onto the principal components, PCA reduces the dimensionality of the data while preserving the variability and relationships between the original variables. This can be useful for various tasks such as data visualization, feature extraction, and noise reduction.
Overall, Principal Component Analysis is a powerful tool for exploratory data analysis and dimensionality reduction, allowing researchers and data scientists to gain insights into complex datasets and simplify subsequent analysis.
Principal Component Analysis (PCA) is a dimensionality reduction technique used to transform a high-dimensional dataset into a smaller set of variables known as principal components. In order to understand how PCA works, it is essential to grasp the mathematical concepts behind it.

The central idea of PCA is to find a linear transformation that produces a new coordinate system in which the variance of the data is maximized along the axes. The first principal component, PC1, captures the maximum variance in the data, with each succeeding component capturing as much remaining variance as possible. This allows us to represent the data in a lower-dimensional space without losing much information.
PCA involves several mathematical concepts that are key to its implementation:
| Covariance Matrix | The covariance matrix measures how variables in a dataset vary together. It is a square matrix that provides a measure of the strength and direction of the linear relationship between pairs of variables. PCA uses the covariance matrix to determine the directions along which the data varies the most. |
| Eigenvalues and Eigenvectors | Eigenvectors represent the directions in which the data varies the most, while eigenvalues represent the amount of variance explained by each eigenvector. PCA calculates the eigenvalues and eigenvectors of the covariance matrix to determine the principal components. |
| Singular Value Decomposition (SVD) | SVD is a matrix factorization method that decomposes a matrix into three separate matrices: U, Σ, and V. PCA utilizes SVD to calculate the eigenvalues and eigenvectors of the covariance matrix efficiently. |
| Projection | Projection involves transforming the original data onto the new coordinate system defined by the principal components. This is achieved by multiplying the original data with the eigenvectors corresponding to the desired number of principal components. |
By understanding these mathematical concepts, one can gain a deeper understanding of how PCA works and how it can be applied to various data analysis tasks. It provides a powerful tool for reducing the dimensionality of complex datasets while retaining essential information.
Principal Component Analysis (PCA) is a widely used statistical technique with various applications in different fields. Below are some common areas where PCA is applied:
Read Also: Understanding the Meaning of 'Invalid Volume' in MT4
1. Dimensionality Reduction:
One of the main applications of PCA is dimensionality reduction. PCA helps in reducing the number of variables in a dataset by creating new variables, called principal components, that capture most of the information present in the original dataset. This is particularly useful in situations where the original dataset has a large number of variables, making it hard to analyze or visualize.
Read Also: Exploring the World of Forex: Unveiling the Most Expensive Forex Signal
2. Data Visualization:
PCA is also used for visualizing high-dimensional data. By reducing the dimensionality of the data, PCA can transform it into a lower-dimensional space that can be easily visualized. This helps in identifying patterns, clusters, and relationships between variables in the data that may not be apparent in the original high-dimensional space.
3. Pattern Recognition:
PCA is commonly used for pattern recognition tasks, such as facial recognition, speech recognition, and handwriting recognition. By reducing the dimensionality of the input data, PCA helps in extracting the most important features and reducing noise or variability in the data. This makes it easier to develop accurate and efficient pattern recognition algorithms.
4. Image Compression:

PCA is widely used in image compression, where the goal is to reduce the size of an image file without significantly compromising its visual quality. By representing the image in terms of principal components, PCA can capture the most important information in the image while discarding less important details. This results in a compressed image file that requires less storage space.
5. Genetics and Genomics:
PCA is frequently used in genetics and genomics research to analyze large datasets of genetic or genomic data. By reducing the dimensionality of the data, PCA can help in identifying genetic patterns or clusters, discovering relationships between genes or samples, and identifying key variables that contribute to genetic variation.
Overall, PCA is a versatile technique with a wide range of applications in various fields. It provides a powerful tool for data analysis, visualization, and pattern recognition, helping researchers and analysts make sense of complex datasets.
Principal Component Analysis (PCA) is a statistical technique used to reduce the dimensionality of a dataset. It transforms the dataset into a new coordinate system where the axes represent the principal components, which are linear combinations of the original variables.
Dimensionality reduction is important in data analysis because it reduces the number of variables, making the dataset more manageable and easier to interpret. It also helps in reducing noise, removing redundancies, and improving computational efficiency.
PCA works by finding the directions, or principal components, of maximum variance in a dataset. It calculates the covariance matrix of the dataset, performs eigendecomposition on the covariance matrix to obtain the eigenvalues and eigenvectors, and then sorts the eigenvectors by their corresponding eigenvalues. The eigenvectors form the new coordinate system, and the eigenvalues represent the amount of variance explained by each principal component.
Eigenvalues play a crucial role in PCA as they represent the amount of variance explained by each principal component. Larger eigenvalues correspond to principal components that capture more of the variability in the data. By examining the magnitude of the eigenvalues, one can determine which principal components are most important in the dataset.
PCA can be used for dimensionality reduction by retaining only the top-k principal components that explain the majority of the variance in the data. By discarding the remaining principal components, the dimensionality of the dataset is reduced while still preserving most of the information. This can be particularly useful when working with high-dimensional datasets where only a subset of the dimensions is relevant.

Best Strategies for Trading Out of the Money Options Out of the money options can be a lucrative way to enhance your trading strategy and potentially …
Read Article
Does eToro use MT4? eToro is a well-known social trading platform that allows users to trade a variety of assets, including stocks, cryptocurrencies, …
Read Article
Understanding the Causes of Seasonal Variation Seasonal variation refers to the changes that occur in various aspects of the natural world throughout …
Read Article
Discover the Forex Millionaire in Nigeria Nigeria, the largest economy in Africa, has seen a surge in the number of individuals making a fortune …
Read Article
Automated Trading: Is it a Good Idea? Automated trading has become increasingly popular in recent years, with many investors turning to this …
Read Article
Is breakout trading profitable? Breakout trading is a popular strategy in the financial markets, where traders aim to profit from the sudden and …
Read Article



