


How to Trade Options in FTSE: A Comprehensive Guide
How to Trade Options on the FTSE This comprehensive guide will provide you with all the information you need to successfully trade options in FTSE. …
Read Article

Missing data is a common issue that can affect the accuracy and reliability of analyses in time series data. Time series data is a sequence of observations collected at regular intervals over time, and missing data can arise due to various reasons such as equipment failure, human error, or data corruption. However, the presence of missing data can pose challenges in conducting meaningful analyses and drawing accurate conclusions.
Dealing with missing data in time series analysis requires careful consideration and application of appropriate strategies. One approach is to ignore the missing data and perform the analysis on the available data only. While this may seem like a straightforward solution, it can lead to biased results and a loss of valuable information. Alternatively, one can choose to impute the missing values using various techniques such as mean imputation, linear interpolation, or multiple imputation.
Another strategy for handling missing data in time series analysis is to use advanced statistical methods that are specifically designed to handle missing values. These methods take into account the temporal nature of the data and can provide more accurate estimates and predictions. Examples of such methods include state space models, dynamic linear models, and structural equation modeling.
It is important to mention that the choice of strategy for handling missing data should be guided by the nature of the data, the research question, and the specific analysis being conducted. Each approach has its own advantages and limitations, and it is crucial to carefully evaluate the implications of the chosen method on the validity and generalizability of the results. By implementing appropriate strategies for handling missing data, researchers can ensure that their time series analyses are robust and reliable.
Key Takeaways:

In time series analysis, missing data refers to the absence of observations at certain time points in a sequence of data points. Missing data can occur for various reasons, such as equipment failure, human error, or simply because the data was not collected at that particular time point.
Handling missing data in time series analysis is crucial because it can affect the accuracy and reliability of the results. Ignoring or improperly handling missing data can lead to biased estimates, reduced statistical power, and incorrect conclusions.
There are several types of missing data patterns that can occur in time series analysis:
Read Also: Who Did the Penguins Trade? Find Out Now | Penguins Trade Tracker
| Pattern | Description |
|---|---|
| Completely Missing | Entire time series is missing for a certain period. |
| Intermittent | Missing data occurs sporadically throughout the time series. |
| Missing at Random (MAR) | The likelihood of missing data depends on observed variables within the dataset. |
| Missing Not at Random (MNAR) | The likelihood of missing data depends on unobserved variables or factors outside the dataset. |
To handle missing data in time series analysis, various strategies can be employed:
Overall, handling missing data in time series analysis requires careful consideration and selection of appropriate techniques. It is essential to understand the nature of the missingness and choose a strategy that minimizes bias and maximizes the accuracy of the analysis.
Missing data is a common problem in time series analysis and can have a significant impact on the accuracy and reliability of the results. Ignoring missing data can lead to biased estimates, incorrect inferences, and reduced model performance. Therefore, it is crucial to properly handle missing data to ensure the integrity and validity of the analysis.
Read Also: Understanding the Distinctions between ESPP and Stock Options
One of the main reasons why handling missing data is important is that missing data can introduce bias into the estimates of time series models. If the missing data is not random and is related to the variable being measured, then ignoring it can result in biased parameter estimates. This can lead to incorrect conclusions and potentially misleading insights.
Another reason why handling missing data is crucial is that it can affect the accuracy and reliability of predictions and forecasts. Time series models are often used to make predictions and forecasts based on historical data. If there are missing values in the historical data, the model may not accurately capture the patterns and trends, leading to inaccurate predictions.
In addition, handling missing data is important for maintaining the integrity of the dataset and ensuring the validity of the analysis. Missing data can create gaps in the time series, which can disrupt the continuity of the data and distort the patterns. Filling in these gaps appropriately can help maintain the integrity of the time series dataset and improve the accuracy of the analysis.
Furthermore, in some cases, missing data can be informative in itself. The fact that data is missing may carry important information and ignoring it can result in the loss of valuable insights. Therefore, properly handling missing data can help preserve the information contained in the missing values and improve the overall reliability and interpretability of the analysis.
In conclusion, handling missing data is of utmost importance in time series analysis. Ignoring missing data can lead to biased estimates, inaccurate predictions, and a loss of valuable information. By properly handling missing data, researchers can enhance the accuracy, reliability, and validity of their time series analysis and ensure that the results are robust and trustworthy.

Missing data in time series analysis refers to the absence of values for certain time points in a sequence of data. This can occur for various reasons such as measurement errors, equipment failures, or simply because the data was not collected at those time points.
Missing data can be a problem in time series analysis because it can lead to biased or inaccurate results. Incomplete data can affect the calculations of statistical measures, such as means or variances, and can also affect the accuracy of forecasting or predictive models.
There are several strategies for handling missing data in time series analysis. One approach is to simply remove the time points with missing data, which is known as complete case analysis. Another approach is to impute or fill in the missing values using techniques such as mean imputation, last observation carried forward, or interpolation techniques.
Mean imputation is a technique for handling missing data in time series analysis where the missing values are replaced with the mean value of the available data. This method assumes that the missing values are missing completely at random and that the mean value is a reasonable estimate of the missing data.
Interpolation techniques should be used to handle missing data in time series analysis when the missing values are believed to be missing at random or when there is a trend or pattern in the data that can be used to estimate the missing values. Interpolation methods can help fill in the missing data points by estimating values based on the surrounding observed data.

How to Trade Options on the FTSE This comprehensive guide will provide you with all the information you need to successfully trade options in FTSE. …
Read Article
Is FX swap an OTC derivative? Introduction: Table Of Contents Is FX Swap an OTC Derivative? Exploring the Characteristics FAQ: What is an FX swap and …
Read Article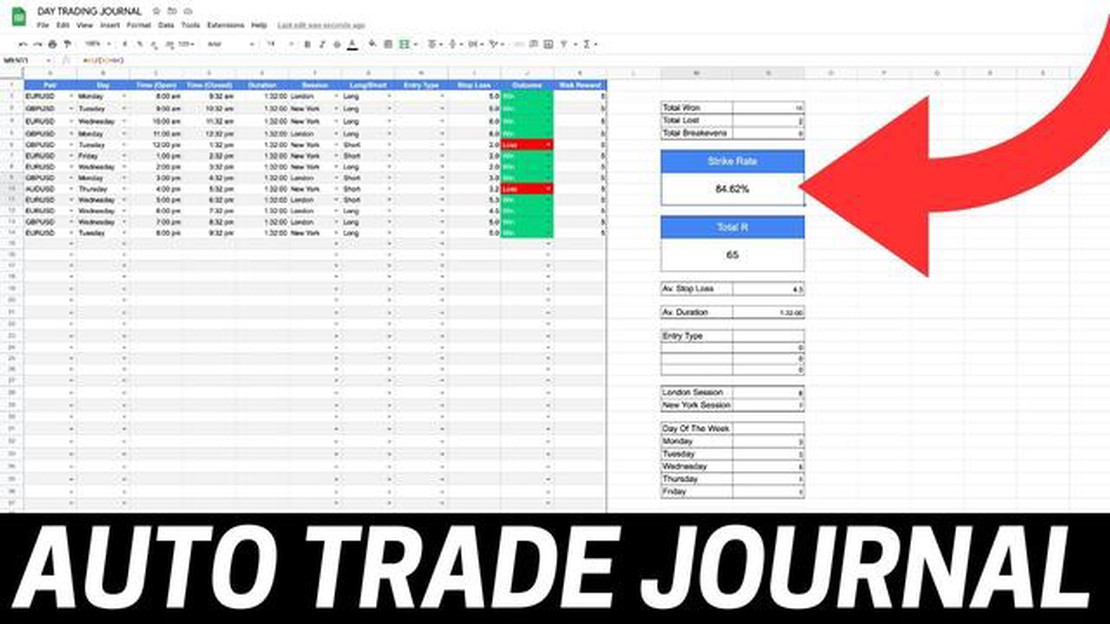
Step by Step Guide: Creating a Money Management Excel Sheet for Trading Managing your money effectively is crucial when it comes to trading. Without a …
Read Article
Top Banks Providing Forex Trading in India Foreign exchange trading, also known as forex trading, has become increasingly popular in India in recent …
Read Article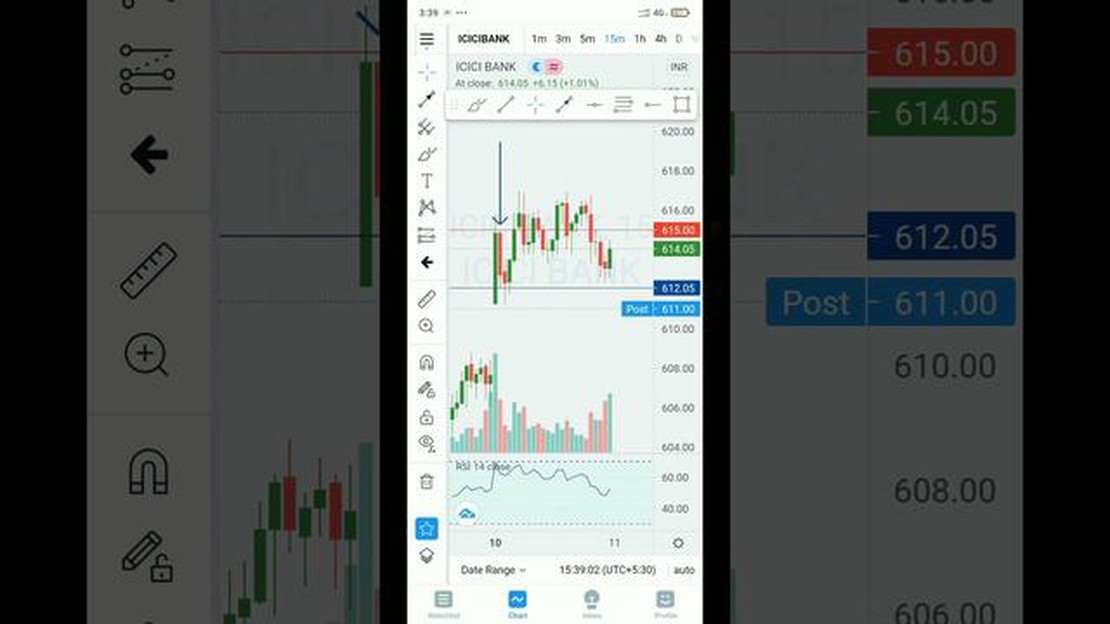
What is the RSI of ICICI Bank? ICICI Bank is a leading Indian multinational banking and financial services company. With a strong presence in the …
Read Article
Understanding the Importance of a Gain Report Gain reports are an essential tool for businesses and individuals who want to understand their financial …
Read Article



