
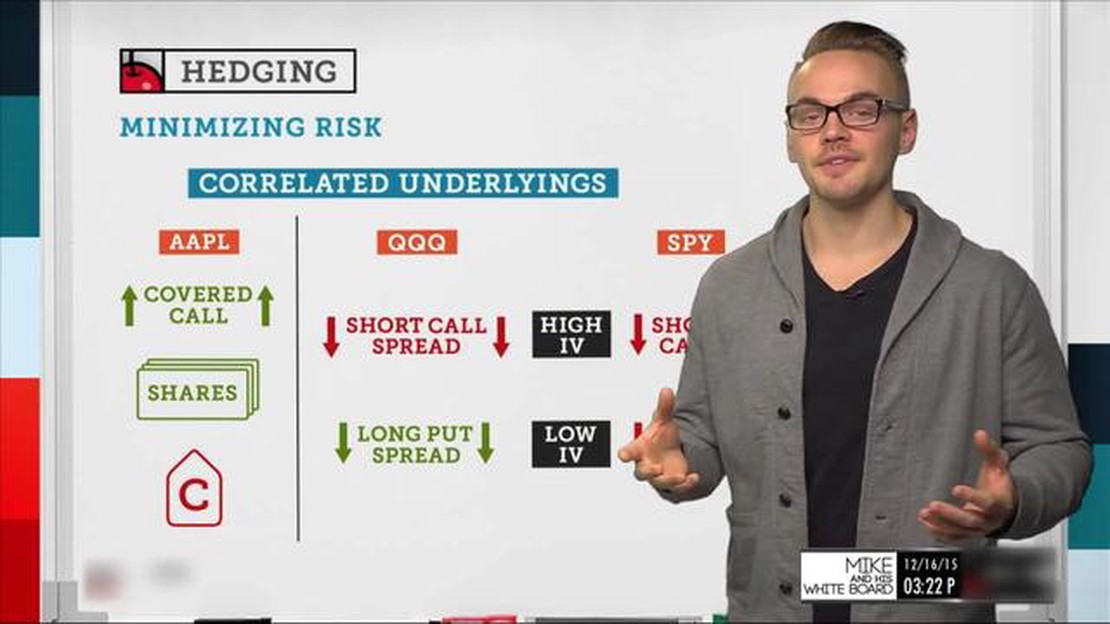

Examples of using options to hedge stock positions
Hedging a Stock with Options: A Practical Example When it comes to the world of investing, risk is inevitable. Whether you are a seasoned trader or a …
Read Article

In the world of statistics, the average is a commonly used measure that provides a snapshot of the central tendency of a dataset. It represents the typical value or the “middle” of a set of numbers. Understanding how to calculate and interpret the average is essential for making sense of data and drawing meaningful conclusions. However, it is equally important to be aware of outliers, which are data points that significantly differ from the majority of the dataset.
Outliers have the potential to distort the average and can greatly impact the analysis and interpretation of data. They can occur due to various reasons, such as measurement errors, data entry mistakes, or extreme values that are genuinely different from the rest of the dataset. It is crucial to identify and handle outliers appropriately to ensure accurate and reliable statistical analysis.
Exploring the concepts of average and outliers involves delving into various statistical measures, including mean, median, and mode. While the mean or arithmetic average is widely used and easy to calculate, it can be sensitive to extreme values. The median, on the other hand, represents the middle value of a dataset when ordered and is less influenced by outliers. The mode is the most frequently occurring value, offering insights into the distribution of data.
For example, let’s consider a set of exam scores: 80, 85, 90, 90, 95, and 65. The average (mean) of this dataset is 84.17, which seems to reflect the overall performance fairly well. However, if we add an outlier, such as a score of 20, the average drops significantly to 68.33, which is not a true representation of the students’ abilities. It is important to look beyond the average and examine the dataset thoroughly to identify and understand outliers.
By understanding the concepts of average and outliers, we can gain deeper insights into datasets and make more informed decisions based on accurate statistical analysis. This article will explore these concepts further, provide examples to illustrate their importance, and offer guidance on how to handle outliers effectively.
In statistics, average refers to the value that represents the central tendency of a set of data. It is also known as the arithmetic mean and is calculated by summing all the values in a data set and then dividing by the number of values.
The average is commonly used to understand the typical value of a dataset. It provides a summary measure that can help in making comparisons and drawing conclusions about the data.
To calculate the average of a dataset, follow these steps:
For example, let’s consider a dataset of test scores:
| Student | Score |
|---|---|
| John | 80 |
| Alice | 90 |
| Bob | 70 |
| Mary | 85 |

To calculate the average test score, we add up all the scores (80 + 90 + 70 + 85 = 325) and divide by the number of students (4). The average test score in this case is 325/4 = 81.25.
The average can be influenced by outliers, which are extreme values that are significantly different from the other values in the dataset. It is important to be aware of outliers when interpreting average values.
Overall, the average provides a useful measure for understanding the central tendency of a dataset, but it should be used in conjunction with other descriptive statistics and considered in the context of the data being analyzed.
An outlier is a data point that is significantly different from other observations in a dataset. It is an extreme value that lies outside the overall pattern of the data. Understanding outliers is important in data analysis because they can have a large impact on statistical results and can potentially indicate errors or unusual patterns in the data.
Read Also: Can I exchange money at NBC? Learn about currency exchange services at NBC
Outliers can occur for various reasons, such as measurement errors, data entry errors, or genuine rare events. They can also be caused by certain statistical distributions or processes. Identifying and dealing with outliers is an important step in data cleansing and pre-processing.
There are different methods to detect and handle outliers. One common approach is to use statistical techniques such as the z-score or the modified z-score, which measure how many standard deviations a data point is away from the mean. Points that fall above a certain threshold, usually set at 2 or 3 standard deviations, are considered outliers.
Another approach is to use box plots, which display the distribution of a dataset and identify outliers as points that lie beyond the whiskers of the plot. Box plots are useful for visualizing the spread of data and identifying any extreme values.
Once outliers are identified, they can be treated in different ways depending on the analysis goals. Outliers can be removed from the dataset, transformed, or replaced with reasonable values. It is important to consider the context and purpose of the analysis before deciding on the appropriate treatment for outliers.
Read Also: Discover the Best Currency Strength Indicator on Tradingview
Understanding outliers is crucial in various fields, such as finance, health care, and social sciences, where extreme values can have a significant impact on the results and interpretations. By carefully analyzing and handling outliers, researchers and analysts can ensure that their conclusions are based on reliable and meaningful data.
In the field of statistics, understanding average and outliers is essential for analyzing data and drawing meaningful conclusions. By exploring these concepts and examples, we can gain a deeper understanding of how they impact our analysis.
When we talk about average or mean, we are referring to the sum of all values divided by the number of values. This provides us with a representative value that gives us an idea of what the typical value in a dataset is. However, it’s important to note that outliers can heavily influence the average, pulling it towards extreme values. This is why it’s important to not solely rely on the average when analyzing data.
Outliers, on the other hand, are data points that significantly differ from the rest of the dataset. These values can be either extremely high or extremely low compared to the other values. Outliers can occur due to various reasons such as data entry errors, measurement errors, or even natural variation in the data. It’s crucial to identify and understand outliers as they can have a significant impact on our analysis and conclusions.

Let’s explore an example to better understand how average and outliers work. Consider a dataset that represents the salaries of employees in a company. The average salary in this dataset is $50,000. However, there is an outlier in the form of a CEO’s salary of $10 million. This outlier heavily skews the average and provides a misleading representation of the typical employee’s salary.
To handle outliers, various techniques can be employed, such as removing the outliers from the dataset, replacing them with more representative values, or using statistical methods that are robust to outliers. The choice of technique depends on the specific context and goals of the analysis.
By exploring concepts and examples related to average and outliers, we can gain a better understanding of how they can impact our analysis. It’s important to be aware of these concepts and employ appropriate techniques to ensure accurate and meaningful interpretations of data.
An average is a measure of central tendency that represents the typical value or the middle value of a set of numbers.
The average is calculated by summing up all the numbers in a set and then dividing that sum by the total number of values in the set.
Outliers are data points that are significantly different from the other data points in a set. They can be much higher or much lower than the average and can have a big impact on the overall analysis.
Outliers are important to consider because they can greatly affect the results and conclusions of data analysis. They can skew the average and make it less representative of the overall data set. By identifying and understanding outliers, we can better understand the distribution and patterns in the data.
Some examples of outliers could be an unusually high income in a dataset of salaries, an unusually low test score in a dataset of exam grades, or an unusually high number of sales in a dataset of daily sales figures.
The purpose of studying average and outliers is to gain a better understanding of data and to identify any unusual or extreme values that might be present in a dataset. By calculating the average, we can determine the typical value or central tendency of a dataset, while analyzing outliers helps us identify any data points that deviate significantly from the average.

Hedging a Stock with Options: A Practical Example When it comes to the world of investing, risk is inevitable. Whether you are a seasoned trader or a …
Read Article
4 Ways Payments are Made: Exploring Different Payment Methods In today’s digital age, there are numerous methods of making payments, each with its own …
Read Article
Understanding the Difference Between Qualified and Nonqualified ISO: Key Factors to Consider An ISO (Incentive Stock Option) is a type of employee …
Read Article
Discover the Profitability of Options Trading Options trading is an exciting and dynamic way to participate in financial markets. By trading options, …
Read Article
Understanding the Difference between Rollover Rate and Swap Rate Rollover rate and swap rate are two terms that often come up in the world of forex …
Read Article
Forex Trader Job Description: What You Need to Know Forex trading, also known as foreign exchange trading, is a fast-paced and dynamic market that …
Read Article



