


Власник Ossia International - розкритий!
Власник Ossia International Компанія Ossia International, світовий лідер у галузі бездротових енергетичних технологій, нарешті розкрила особу свого …
Прочитати статтю

У світі аналізу часових рядів модель ARIMA є популярним вибором для моделювання та прогнозування даних. ARIMA розшифровується як авторегресійне інтегроване ковзне середнє і поєднує в собі концепції авторегресії, диференціювання та ковзного середнього, щоб відобразити складні закономірності в даних часових рядів. У цьому вичерпному посібнику ми зосередимося саме на компоненті ковзного середнього в моделі ARIMA.
Модель ковзного середнього, також відома як модель MA, є ключовим компонентом ARIMA. Вона допомагає врахувати випадкові компоненти або шум, присутні в даних часових рядів. Модель MA базується на ідеї, що значення часового ряду в будь-якій точці є лінійною комбінацією минулих помилок, також відомих як залишки.
Модель ковзного середнього визначається двома основними параметрами - порядком диференціювання (d) та порядком ковзного середнього (q). Порядок диференціювання визначає, скільки разів потрібно диференціювати часовий ряд, щоб зробити його стаціонарним, в той час як порядок ковзного середнього визначає кількість членів похибки, які будуть включені в модель. Розуміючи і правильно визначивши ці параметри, ми можемо побудувати точну і ефективну модель ковзного середнього для аналізу і прогнозування даних часових рядів.
У цьому посібнику ми детально розглянемо концепцію моделі ковзного середнього, включаючи її математичне формулювання, інтерпретацію параметрів, а також кроки для побудови та оцінки моделі. Ми також обговоримо практичні приклади та тематичні дослідження, щоб проілюструвати її застосування в реальних сценаріях. Наприкінці цього посібника ви матимете повне уявлення про модель ковзного середнього в ARIMA і зможете застосувати її до власних даних часових рядів.
У контексті ARIMA модель ковзного середнього (Moving Average, MA) є ключовим компонентом, який допомагає в аналізі та прогнозуванні даних часових рядів. Її основна увага зосереджена на залежності між спостереженням і залишковою похибкою від процесу ковзного середнього.

Модель MA складається з трьох основних компонентів:
Модель MA може бути представлена у вигляді:
Xt = μ + εt + θ1εt-1 + θ2εt-2 + … + θqεt-q
Тут Xt представляє часовий ряд в момент часу t, μ - константа, εt - випадкова похибка в момент часу t, θi - коефіцієнти MA моделі, а q - порядок MA моделі.
Читайте також: Розрахунок IRD: покроковий посібник з визначення різниці відсоткових ставок
Модель MA відображає короткострокові залежності та коливання часових рядів шляхом моделювання зв’язку між спостереженнями та залишковими помилками. Вона особливо корисна у випадках, коли часовий ряд демонструє випадкову або непередбачувану поведінку.
Аналізуючи компоненти моделі MA та оцінюючи значення параметрів, ми можемо отримати уявлення про основні закономірності та тенденції часового ряду. Це, в свою чергу, дозволяє робити точні прогнози і передбачення на основі спостережуваних даних.
Модель ковзного середнього (MA) є важливим компонентом моделі авторегресійного інтегрованого ковзного середнього (ARIMA). Вона використовується для розуміння і прогнозування поведінки даних часових рядів. У цьому розділі ми розглянемо, як застосовувати модель ковзного середнього в рамках ARIMA.
У моделі ARIMA компонент ковзного середнього відповідає за врахування короткострокових коливань у даних. Це допомагає згладити шум і виявити будь-які основні закономірності або тенденції. Щоб застосувати модель ковзного середнього в ARIMA, нам потрібно зрозуміти, як вибрати відповідний порядок моделі.
Порядок моделі ковзного середнього позначається як MA(q), де “q” - це кількість членів ковзного середнього із запізненням, які потрібно включити в модель. Запізнілі члени ковзної середньої є середньозваженим значенням минулих помилок. Важливо вибрати відповідне значення для “q”, щоб точно відобразити короткострокову динаміку даних.
Існує кілька способів визначити порядок моделі ковзного середнього. Одним із поширених підходів є використання графіків автокореляційної функції (ACF) та часткової автокореляційної функції (PACF). Графік ACF допомагає визначити потенційний порядок компонента ковзного середнього, тоді як графік PACF допомагає визначити порядок компонента авторегресії.
Читайте також: Дізнайтеся, як додати просту ковзаючу середню в MT4 за допомогою цього покрокового керівництва
Інший підхід полягає у використанні інформаційних критеріїв, таких як інформаційний критерій Акаіке (AIC) та байєсівський інформаційний критерій (BIC). Ці критерії забезпечують баланс між складністю моделі та її відповідністю, дозволяючи нам вибрати найкращий порядок для моделі ковзного середнього.
Після того, як ми визначили порядок моделі ковзного середнього, ми можемо оцінити параметри моделі, використовуючи такі методи, як оцінка максимальної правдоподібності. Оцінка параметрів моделі дозволяє нам робити прогнози і передбачати майбутні значення на основі спостережуваних даних.
Загалом, модель ковзного середнього є потужним інструментом для аналізу даних часових рядів. Застосовуючи її в рамках ARIMA, ми можемо точно вловити короткострокову динаміку і зробити значущі прогнози. Розуміння того, як вибрати відповідний порядок та оцінити параметри моделі, має вирішальне значення для отримання надійних результатів.
Модель ковзного середнього в ARIMA - це статистичний метод, який використовується для прогнозування майбутніх значень часового ряду на основі середнього значення попередніх значень ряду. Це компонент моделі ARIMA, що розшифровується як Авторегресійне інтегроване ковзне середнє.

Модель ковзного середнього відрізняється від інших моделей, таких як авторегресійна модель, тим, що вона враховує середнє попередніх значень ряду, а не тільки самі попередні значення. Це допомагає згладити будь-які нерівності або коливання в даних і забезпечує більш точний прогноз.
Існує декілька переваг використання моделі ковзного середнього в ARIMA. По-перше, вона допомагає усунути будь-які короткострокові коливання в даних, забезпечуючи більш стабільний і точний прогноз. По-друге, це відносно проста модель для розуміння та застосування. Нарешті, її можна використовувати для прогнозування майбутніх значень часового ряду з високим рівнем точності.
Так, модель ковзного середнього в ARIMA можна використовувати для будь-якого типу даних часових рядів, якщо ці дані демонструють певну форму тренду або сезонності. Однак важливо зазначити, що модель ковзного середнього може не підходити для всіх типів даних, і для отримання більш точного прогнозу може знадобитися використання інших моделей, таких як авторегресійна модель, у поєднанні з нею.

Власник Ossia International Компанія Ossia International, світовий лідер у галузі бездротових енергетичних технологій, нарешті розкрила особу свого …
Прочитати статтю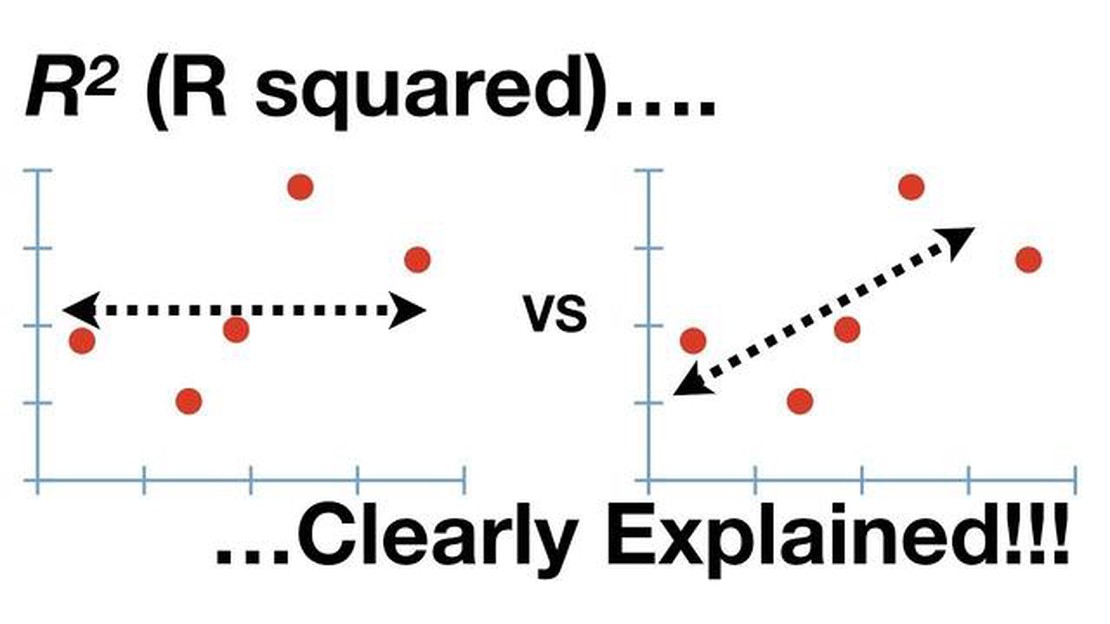
Чи добре 50% R Square? При аналізі даних і запуску регресійних моделей однією з найпоширеніших мір хорошого узгодження є статистика R Квадрат (R^2). R …
Прочитати статтю
Дізнайтеся, чому люди люблять торгувати на Форекс За останні роки торгівля на ринку Форекс стала неймовірно популярною формою інвестування, і це не …
Прочитати статтю
Що таке АТ&? AT&T, одна з провідних телекомунікаційних компаній у світі, нещодавно оприлюднила свій прогноз на 2023 рік. Цей прогноз дає уявлення про …
Прочитати статтю
Оподаткування прибутку від фондових опціонів Опціони на акції є популярною формою компенсації для працівників і можуть забезпечити значні фінансові …
Прочитати статтю
Як розрахувати середню зарплату онлайн Обчислення середнього значення, або середнього показника, є фундаментальною концепцією в математиці та …
Прочитати статтю



