


Короткий посібник: Як легко знайти свій номер IBAN
Як знайти свій номер IBAN? Вам коли-небудь потрібно було знайти свій номер IBAN, але ви не знали, з чого почати? Не хвилюйтеся, ми вам допоможемо! У …
Прочитати статтю

Машини опорних векторів (SVM) - це потужний алгоритм машинного навчання, який широко використовується для задач класифікації та регресії. Він працює шляхом пошуку оптимальної гіперплощини, яка розділяє точки даних на різні класи. SVM відомий своєю здатністю обробляти дані високої розмірності та стійкістю до викидів.
Однією з головних переваг SVM є його гнучкість. Його можна використовувати як для лінійних, так і для нелінійних задач класифікації, використовуючи різні типи ядер. Найчастіше використовуються лінійні, поліноміальні, радіально-базисні функції (RBF) та сигмоїдні ядра. Кожне ядро має свої особливості і може бути обрано залежно від конкретної задачі.
SVM особливо корисна, коли дані не є лінійно роздільними. Він може обробляти складні межі рішень і здатен вловлювати нелінійні зв’язки між ознаками та цільовою змінною. SVM також відомий своєю здатністю ефективно обробляти великі набори даних, оскільки він спирається лише на підмножину навчальних даних, які називаються опорними векторами.
Ще однією перевагою SVM є його здатність обробляти дані високої розмірності. Він може ефективно обробляти велику кількість ознак без перенавчання, на відміну від деяких інших алгоритмів машинного навчання. Це робить SVM популярним вибором у багатьох галузях, включаючи комп’ютерний зір, біоінформатику та класифікацію текстів.
Отже, машини опорних векторів (SVM) - це універсальний алгоритм машинного навчання, який можна використовувати в широкому спектрі застосувань. Незалежно від того, працюєте ви з лінійними чи нелінійними даними, SVM пропонує потужний інструмент для задач класифікації та регресії. Здатність обробляти дані високої розмірності та стійкість до викидів роблять його популярним серед науковців з даних та спеціалістів з машинного навчання.
Машини опорних векторів (SVM) - це потужний алгоритм машинного навчання, який широко використовується для задач класифікації та регресії. SVM - це керований алгоритм навчання, який аналізує дані і знаходить найкращу границю рішення, яка розділяє класи або прогнозує безперервну цільову змінну.
Основна ідея SVM полягає в тому, щоб знайти гіперплощину в просторі вищої розмірності, яка найкраще розділяє навчальні дані на різні класи. Простіше кажучи, SVM знаходить оптимальну лінію або гіперплощину, яка максимізує відстань між класами. Ця оптимальна лінія або гіперплощина вибирається таким чином, щоб максимально розділити точки даних з різних класів. SVM може обробляти як лінійно розділені, так і нелінійно розділені дані, використовуючи різні функції ядра.
Як працює SVM? Розглянемо випадок бінарної класифікації. У SVM кожна точка даних представляється у вигляді вектора ознак у просторі вищої розмірності на основі її характеристик. Потім алгоритм SVM відображає ці дані у вимірний простір, де він намагається знайти оптимальну гіперплощину, яка розділяє два класи з максимальним відривом.
Відстань визначається як перпендикулярна відстань від гіперплощини до найближчих точок даних кожного класу. SVM прагне максимізувати цю відстань, оскільки вважає, що більша відстань призводить до кращого узагальнення і меншої помилки на невидимих даних.
У випадку, якщо класи не є ідеально відокремлюваними, SVM допускає деяку помилкову класифікацію, вводячи “м’яку межу”. М’яка межа дозволяє неправильно класифікувати деякі точки даних і робить модель більш гнучкою та надійною. Штраф за неправильну класифікацію контролюється параметром регуляризації, який допомагає визначити баланс між розміром маржі та помилкою неправильної класифікації.
SVM також може обробляти дані, що нелінійно розділяються, завдяки трюку ядра. Трюк ядра дозволяє SVM трансформувати дані у простір вищої розмірності, де вони стають лінійно роздільними. SVM використовує різні функції ядра, такі як лінійна, поліноміальна, радіально-базисна функція (RBF) та сигмоїдальна, щоб відобразити дані в цей простір вищої розмірності.
Отже, SVM - це потужний алгоритм машинного навчання, який знаходить найкращу межу рішення для розділення або прогнозування різних класів або цілей регресії. Він працює шляхом пошуку оптимальної гіперплощини у просторі вищої розмірності, яка максимізує відстань між класами. SVM може обробляти лінійно відокремлювані та нелінійно відокремлювані дані за допомогою різних функцій ядра, що робить його універсальним алгоритмом для різних завдань класифікації та регресії.
1. Задачі класифікації:.
SVM зазвичай використовуються для задач бінарної класифікації, де метою є розділення точок даних на два різні класи. Наприклад, SVM можна використовувати для класифікації електронних листів на спам і неспам, прогнозування відтоку клієнтів або визначення, чи є у пацієнта хвороба чи ні.
2. Аналіз тексту та настроїв:.
SVM широко використовуються в задачах обробки природної мови. Їх можна використовувати для аналізу настроїв, де метою є визначення настрою (позитивного, негативного або нейтрального) певного тексту або відгуку. SVM також можна використовувати для категоризації текстів, класифікації документів і кластеризації текстів.
3. Розпізнавання зображень
SVM ефективні в задачах розпізнавання зображень, таких як виявлення об’єктів і розпізнавання облич. Їх можна навчити класифікувати зображення за різними категоріями, наприклад, визначати, чи містить зображення автомобіль або людину. SVM також використовуються для розпізнавання виразу обличчя та сегментації зображень.
Читайте також: Освоєння просунутої цінової дії: Найкращі поради та стратегії для навчання
4. Біоінформатика:
SVM знайшли численні застосування в біоінформатиці, включаючи класифікацію білків, аналіз експресії генів та аналіз послідовності ДНК. SVM можна використовувати для прогнозування функцій білків або класифікації генів на основі їхньої експресії, що допомагає в розумінні біологічних процесів і захворювань.
5. Виявлення шахрайства:.
ШНМ можна використовувати для виявлення шахрайства в різних сферах, наприклад, для виявлення шахрайства з кредитними картками або для виявлення шахрайства зі страховими відшкодуваннями. Навчаючи SVM на історичних даних про шахрайство, вона може виявляти закономірності та аномалії в нових даних і позначати потенційні шахрайські транзакції.
6. Розпізнавання рукописного тексту:.
ШНМ успішно використовуються для розпізнавання рукописного тексту, дозволяючи машинам розпізнавати та інтерпретувати рукописний текст. ШНМ можна навчити на наборі даних рукописних символів, а потім використовувати для класифікації нового рукописного введення.
Читайте також: Кращі торгові журнали для ф'ючерсів на Binance: Знайдіть найкращий варіант
7. Системи рекомендацій:.
SVM можна використовувати в рекомендаційних системах, щоб пропонувати користувачам релевантні продукти або послуги. Аналізуючи поведінку та вподобання користувачів, SVM можуть передбачати їхні уподобання та надавати персоналізовані рекомендації.
8. Аналіз часових рядів:.

SVM використовуються в аналізі часових рядів для прогнозування майбутніх значень або виявлення закономірностей у послідовних даних. SVM можна застосовувати для прогнозування фінансових ринків, прогнозування цін на акції, прогнозування погоди та інших залежних від часу наборів даних.
9. Медична діагностика
SVM можуть допомогти в медичній діагностиці, аналізуючи дані про пацієнта, такі як симптоми, історія хвороби та результати аналізів. Їх можна навчити класифікувати пацієнтів за різними категоріями захворювань, допомагати у прогнозуванні наслідків хвороби або визначенні потенційних факторів ризику.
10. Виявлення аномалій:.
SVM можна використовувати для виявлення аномалій у різних сферах, таких як виявлення вторгнень у мережу, виявлення шахрайства або виявлення збоїв у роботі обладнання. Навчивши SVM на нормальних моделях поведінки, вона може ідентифікувати відхилення або викиди в нових даних, що дозволяє виявити аномалії на ранніх стадіях.
Загалом, SVM є універсальними і можуть застосовуватися до широкого спектру областей і проблем. Здатність обробляти багатовимірні дані, мати справу з нелінійними зв’язками і вирішувати завдання бінарної та багатокласової класифікації робить їх цінним інструментом у багатьох реальних додатках.
Машина опорних векторів (SVM) - це керований алгоритм машинного навчання, який можна використовувати як для класифікації, так і для регресії. Він працює шляхом пошуку найкращої гіперплощини, яка розділяє точки даних на різні класи.
Масиви опорних векторів мають кілька переваг, серед яких здатність обробляти дані високої розмірності, здатність обробляти як лінійні, так і нелінійні дані, а також здатність обробляти дані з великою кількістю ознак. Вони також менш схильні до перенавчання порівняно з іншими алгоритмами.
Вам слід розглянути можливість використання машин на основі опорних векторів, якщо перед вами стоїть завдання класифікації або регресії, і у вас є відносно невеликий набір даних з помірною кількістю ознак. SVM також добре працюють, коли дані нелінійно розділяються або коли в даних є шум.
Так, машини опорних векторів чутливі до викидів. Викиди можуть мати значний вплив на положення та орієнтацію гіперплощини, що може призвести до поганої роботи алгоритму. Попередня обробка даних для видалення викидів або використання надійних версій SVM може допомогти зменшити вплив викидів.
Масиви опорних векторів можуть обробляти незбалансовані набори даних, але вони можуть не працювати належним чином, якщо дисбаланс дуже сильний. У таких випадках для покращення продуктивності SVM можна використовувати такі методи, як надмірна вибірка класу меншості, недостатня вибірка класу більшості або використання вагових коефіцієнтів класів.
Машина опорних векторів (SVM) - це керований алгоритм машинного навчання, який використовується для задач класифікації та регресії. Він працює шляхом пошуку найкращої можливої гіперплощини у багатовимірному просторі ознак для розділення різних класів або прогнозування безперервних значень.
Існує кілька переваг використання машин опорних векторів (SVM). По-перше, SVM ефективні у просторах високої розмірності, що робить їх придатними для задач з великою кількістю ознак. По-друге, SVM часто забезпечують хорошу продуктивність узагальнення, що означає, що вони можуть точно класифікувати невидимі дані. Нарешті, SVM можуть обробляти нелінійні межі рішень завдяки використанню функцій ядра.

Як знайти свій номер IBAN? Вам коли-небудь потрібно було знайти свій номер IBAN, але ви не знали, з чого почати? Не хвилюйтеся, ми вам допоможемо! У …
Прочитати статтю
Де знайти курси валют Коли справа доходить до курсів обміну валют, пошук найкращої пропозиції може заощадити вам значну суму грошей. Незалежно від …
Прочитати статтю
Розуміння середнього значення та відхилень У світі статистики середнє значення - це загальновживаний показник, який дає уявлення про основну тенденцію …
Прочитати статтю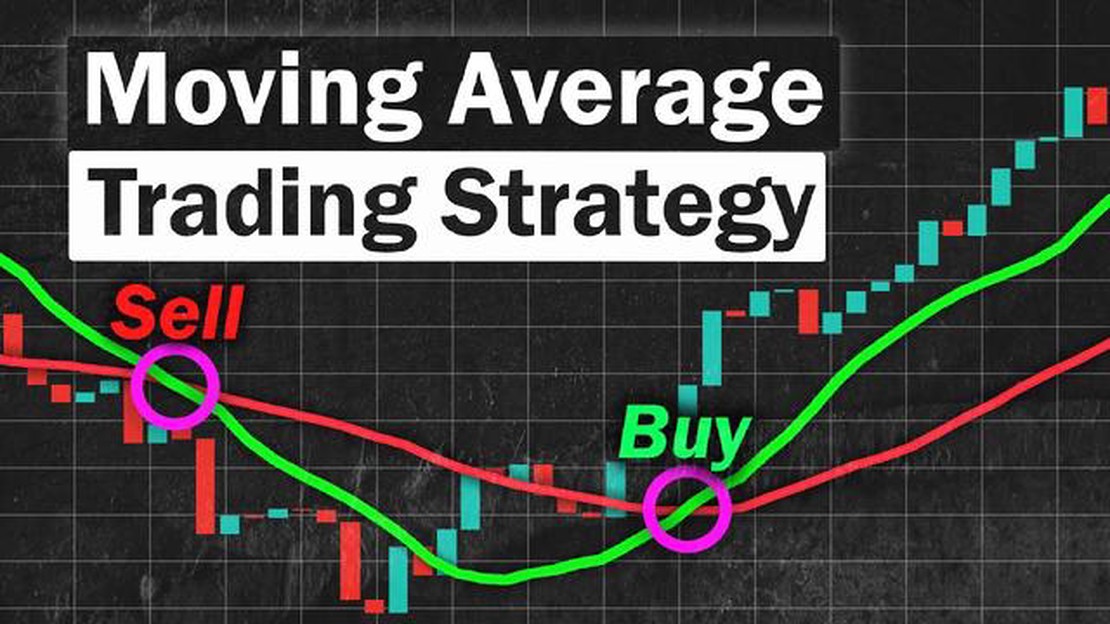
Налаштування EMA для торгівлі на Форекс Коли мова йде про торгівлю на Форекс, одним з найпопулярніших технічних індикаторів, що використовуються …
Прочитати статтю
Кращі платформи для торгівлі опціонами: Де торгувати опціонами **Торгівля опціонами - це популярна інвестиційна стратегія, яка дозволяє трейдерам …
Прочитати статтю
Чи є eToro бінарним? Торгівля бінарними опціонами - це популярний метод фінансової торгівлі, в якому трейдери можуть вибирати між двома можливими …
Прочитати статтю



