



Чи можна торгувати опціонами з будь-якими власними торговими компаніями?
Торгівля опціонами на проп-фірмах: Ваш повний посібник Торгівля опціонами - популярна і потенційно прибуткова інвестиційна стратегія. Вона дозволяє …
Прочитати статтю
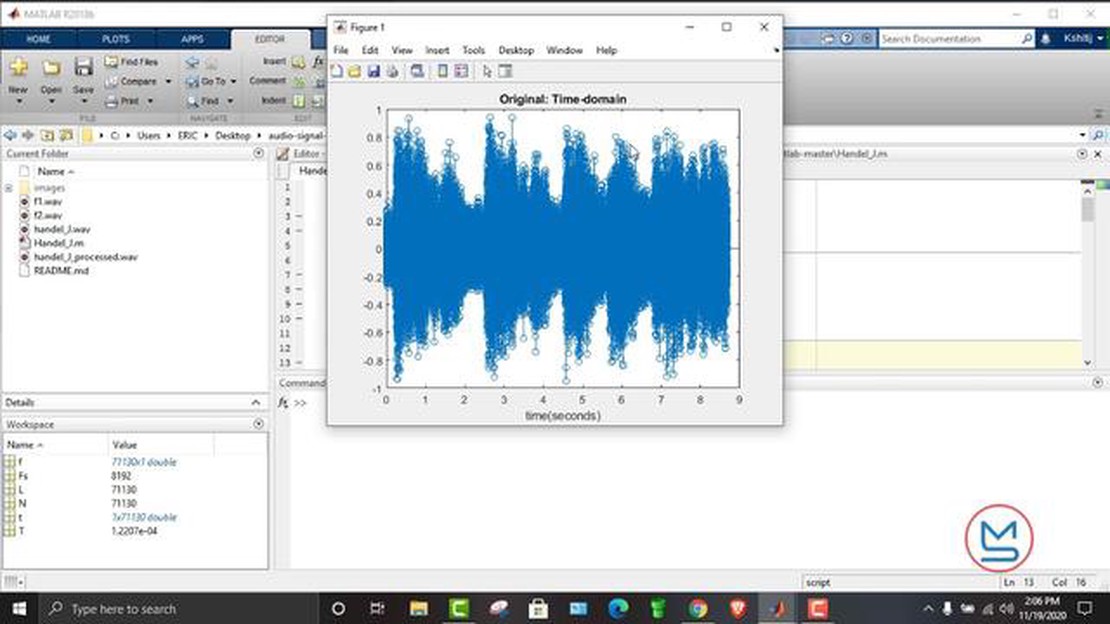
Шум є поширеною і часто неминучою проблемою при роботі з даними. Він може суттєво спотворювати або приховувати основні закономірності та взаємозв’язки в даних, що ускладнює отримання значущих висновків або точних прогнозів. Для того, щоб отримати цінну інформацію із зашумлених даних, важливо використовувати ефективні методи фільтрації шуму.
Одним із поширених підходів до фільтрації шуму є використання статистичних методів. Ці методи використовують статистичні моделі для виявлення та видалення з даних викидів або інших видів шуму. Кількісно оцінюючи невизначеність і мінливість даних, методи статистичної фільтрації можуть допомогти відрізнити випадкові флуктуації від справжнього сигналу. Це може бути особливо корисно в таких галузях, як фінанси, де точні прогнози залежать від виявлення значущих закономірностей серед ринкового шуму.
Іншим підходом до фільтрації шуму є використання методів цифрової обробки сигналів. Ці методи широко застосовуються в таких галузях, як обробка аудіо та зображень, де небажаний шум може значно погіршити якість сигналу. Цифрові фільтри, такі як низькочастотні або високочастотні фільтри, можна використовувати для вибіркового послаблення або усунення певних частот шуму, зберігаючи при цьому бажаний сигнал. Ці методи можуть бути ефективними для зменшення шуму, спричиненого такими факторами, як електричні перешкоди або артефакти датчиків.
Алгоритми машинного навчання також пропонують перспективні методи фільтрації шуму. Ці алгоритми можна навчити розпізнавати шаблони і закономірності в даних, що дозволяє їм розрізняти сигнал і шум. Навчаючись на маркованих прикладах, моделі машинного навчання можуть розробляти складні правила фільтрації, які адаптуються до конкретних характеристик даних. Це може бути особливо корисно в таких сферах, як класифікація текстів, де шум може бути у вигляді нерелевантної або оманливої інформації.
Хоча не існує універсального рішення для фільтрації шуму, комбінація цих методів часто дає найкращі результати. Поєднуючи статистику, цифрову обробку сигналів і машинне навчання, дослідники і практики можуть розробити надійні методи фільтрації шуму, пристосовані до конкретних характеристик своїх даних. Завдяки здатності ефективно відфільтровувати шум аналітики даних можуть виявляти приховані закономірності та кореляції, що призводить до більш точних прогнозів та прийняття обґрунтованих рішень.
Шум - це небажані і випадкові варіації або помилки, які можуть бути присутніми в даних. Він може впливати на точність і надійність аналізу даних і може призвести до неправильних висновків або рішень. Розуміння поширених типів шуму в даних є важливим для розробки ефективних методів фільтрації шуму та покращення якості даних.
Нижче наведено кілька найпоширеніших типів шуму в даних:
| Тип шуму Опис | |
|---|---|
| Випадковий шум - випадкові варіації, які виникають через численні фактори, такі як помилки вимірювання, умови навколишнього середовища або непередбачувані події. Він може вносити неузгодженості та коливання в дані. | |
| Систематичний шум - шум, який виникає через систематичну помилку або упередженість у процесі збору даних. Він може бути спричинений проблемами з калібруванням інструменту, зміщенням вимірювань або несправним обладнанням. Систематичний шум часто є послідовним і може впливати на весь набір даних або певні піднабори даних. | |
| Фоновий шум - це небажані сигнали або перешкоди, які присутні в даних через зовнішні джерела. Він може бути спричинений електричними перешкодами, електромагнітним випромінюванням або іншими факторами навколишнього середовища. Фоновий шум може маскувати або спотворювати потрібні сигнали в даних. | |
| Викиди (Outliers) Викиди - це екстремальні значення або точки даних, які значно відхиляються від решти набору даних. Вони можуть бути спричинені помилками вимірювання, помилками введення даних або рідкісними подіями. Викиди можуть вносити шум і впливати на статистичний аналіз і моделювання даних. | |
| Відсутні дані Відсутні дані - це відсутність або неповна інформація в наборі даних. Це може статися з різних причин, таких як помилки збору даних, втрата даних під час передачі або відсутність відповідей в опитуваннях. Відсутні дані можуть вносити шум і впливати на аналіз та інтерпретацію даних. |
Виявлення та розуміння конкретних типів шуму, присутніх у даних, має вирішальне значення для застосування відповідних методів фільтрації шуму. Різні типи шуму можуть вимагати різних підходів до зменшення шуму та очищення даних. Ефективно фільтруючи шум з даних, дослідники та аналітики можуть підвищити точність і надійність своїх висновків і приймати більш обґрунтовані рішення на основі даних.
Читайте також: Розуміння різниці між моделями Доджі та вечірньої зірки
При роботі з зашумленими даними дуже важливо застосовувати відповідні методи фільтрації шуму для отримання точних і надійних результатів. Ось кілька найпоширеніших методів фільтрації шуму:
Вибір найбільш підходящого методу фільтрації шуму залежить від конкретних характеристик шуму і бажаного результату. Часто необхідно спробувати різні методи і налаштувати їх параметри для досягнення оптимального результату.
Читайте також: Стокгольмська крона до індійської рупії: Обмінний курс і конвертація
Фільтрація шуму є важливим процесом в аналізі даних і має численні переваги. Ось деякі з ключових переваг:
Загалом, фільтрація шуму відіграє важливу роль в аналізі даних і має кілька переваг. Вона підвищує точність, покращує процес прийняття рішень, сприяє ефективній обробці даних, забезпечує кращу візуалізацію даних, зменшує вимоги до зберігання і мінімізує помилкові тривоги. Впроваджуючи ефективні методи фільтрації шуму, організації можуть отримувати цінну інформацію та приймати обґрунтовані рішення на основі надійних і значущих даних.
Шум у даних - це нерелевантні або випадкові флуктуації чи збурення, які можуть виникати в наборах даних. Він може впливати на точність аналізу, вносячи помилки або неузгодженості в дані, що ускладнює отримання точних висновків або надійних прогнозів.
Поширеними джерелами шуму в даних є помилки вимірювання, шуми датчиків, помилки передачі даних, викиди в наборі даних, а також нерелевантна або надлишкова інформація. Інші джерела можуть включати фактори навколишнього середовища, людські помилки або збої в роботі системи.

Існує кілька ефективних методів фільтрації шуму з даних, зокрема:
Ковзне середнє передбачає обчислення середнього значення ковзного вікна точок даних. Його можна використовувати для фільтрації шуму в даних, згладжуючи коливання і зменшуючи вплив окремих викидів або випадкових коливань. Розмір вікна можна регулювати, щоб контролювати рівень згладжування, причому більші розміри вікна забезпечують більш поступовий ефект фільтрації.
Вейвлет-згладжування - це метод, який використовується для видалення шуму з даних зі збереженням важливих характеристик даних. Він працює шляхом розкладання даних на різні частотні компоненти за допомогою вейвлет-перетворень. Високочастотні компоненти, які часто асоціюються з шумом, потім відфільтровуються або зменшуються за величиною. Потім деноміновані дані реконструюються з використанням частотних компонентів, що залишилися.
Найпоширенішими джерелами шуму в даних є помилки вимірювання, електронні перешкоди, нерелевантні змінні та помилки при введенні даних.

Торгівля опціонами на проп-фірмах: Ваш повний посібник Торгівля опціонами - популярна і потенційно прибуткова інвестиційна стратегія. Вона дозволяє …
Прочитати статтю
Що означає, коли запас нижче 200 DMA? Коли справа доходить до аналізу тенденцій на фондовому ринку та прийняття інвестиційних рішень, одним з ключових …
Прочитати статтю
Чи безпечно використовувати Odin? Odin - це популярний програмний інструмент, який часто використовується ентузіастами та розробниками Android для …
Прочитати статтю
Скільки коштує 1к срібла? Срібло - це дорогоцінний метал, який протягом тисячоліть використовувався як засіб обміну, засіб збереження вартості та …
Прочитати статтю
Книги для навчання торгівлі на Форекс: Цінні посібники для досягнення успіху Торгівля на ринку Форекс - це складна і висококонкурентна сфера, яка …
Прочитати статтю
Хто може торгувати F&? Якщо ви зацікавлені в торгівлі, важливо знати, хто може брати участь у ринку F&. Ринок F& відкритий як для фізичних, так і для …
Прочитати статтю



