


What is ATR (Average True Range) and how to use it in trading?
How to Use ATR (Average True Range) In the world of financial trading, there are numerous technical indicators that traders use to analyze price …
Read Article
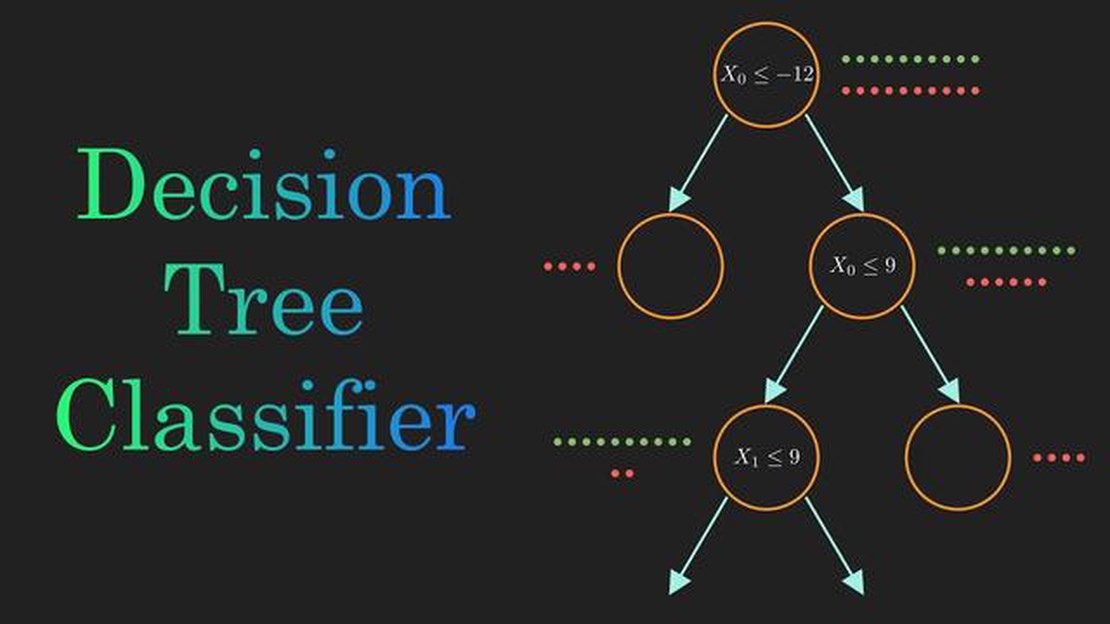
Decision trees and neural networks are two widely used machine learning models that are employed for solving classification and regression problems. While both models aim to make predictions based on input data, they have distinct differences in terms of structure and functioning.
A decision tree is a hierarchical model that builds a tree-like structure where each internal node represents a feature, each branch represents a decision rule, and each leaf node represents a class label or a regression value. It is a transparent model that can be easily visualized and understood, making it popular in domains where interpretability is crucial. Decision trees are suitable for problems with discrete and continuous input variables, and they can handle both categorical and numerical output variables.
On the other hand, a neural network is a complex interconnected network of artificial neurons, inspired by the structure of a biological brain. Each neuron in a neural network performs a weighted sum of its inputs, applies an activation function, and passes the output to the next layer of neurons. Neural networks are known for their ability to learn complex patterns and relationships in data, making them suitable for problems with high-dimensional input features. They are often used in applications like image recognition, speech processing, and natural language processing.
One major difference between decision trees and neural networks is the way they learn from data. Decision trees use a greedy approach to recursively split the data based on the features that provide the most information gain or Gini impurity reduction. This top-down learning process continues until a stopping criterion is met. Neural networks, on the other hand, use a gradient-based optimization algorithm, such as backpropagation, to iteratively update the weights and biases of the neurons to minimize a loss function. This bottom-up learning process requires a large amount of labeled training data and computational resources.
A decision tree is a simple yet powerful machine learning algorithm that is widely used in various applications. It is a flowchart-like structure in which each internal node represents a feature (or attribute), each branch represents a decision rule, and each leaf node represents the outcome.
In a decision tree, the data is split into subsets based on the values of certain features. This split is determined by a decision rule that is chosen based on a specific criterion, such as information gain or Gini impurity. The goal is to create a tree that is as small as possible while still classifying the data accurately.

Decision trees can be used for both classification and regression tasks. In classification, each leaf node corresponds to a class label, while in regression, each leaf node corresponds to a numerical value. The decision rules in a decision tree can be interpreted as “if-then” statements, making it easy to understand and interpret the model.
One of the main advantages of decision trees is that they can handle both categorical and numerical features. They can also handle missing values in the data by using different algorithms, such as imputation or surrogate splits.
Decision trees have a number of other properties that make them useful in various scenarios. They are computationally efficient, easy to interpret, and can handle both small and large datasets. However, decision trees are prone to overfitting, especially when the tree becomes too large or when the data is noisy. To overcome this issue, ensemble methods, such as random forests or gradient boosting, can be used.
In summary, decision trees are a versatile and powerful machine learning algorithm that can be used for both classification and regression tasks. They are easy to interpret and handle both categorical and numerical features. However, they are prone to overfitting and may require additional techniques to improve their performance.
Decision trees and neural networks are both powerful machine learning algorithms that are widely used for classification and regression tasks.
Read Also: What is Included in a WGA Deal? Exploring the Benefits and Terms
Decision trees are a type of predictive model that uses a tree-like structure to represent decisions and their possible consequences. Each internal node of the tree represents a decision based on a specific feature, and each leaf node represents a prediction or a decision outcome. Decision trees are easy to interpret and understand, making them suitable for applications where explainability is important. They can be used for both classification and regression tasks, and are particularly useful when dealing with categorical or discrete input features.
On the other hand, neural networks are a type of computational model inspired by the structure and function of the human brain. They are composed of interconnected nodes, called neurons, that work together to process and transmit information. Neural networks can learn complex patterns and relationships in the data by adjusting the strength of connections between neurons, a process known as training. They are known for their ability to handle large amounts of data and capture subtle patterns, making them suitable for tasks such as image and speech recognition. Neural networks are also used for classification and regression tasks, and are especially effective when dealing with continuous or numeric input features.
Read Also: Can the options Max Pain theory help predict stock price movements?
In summary, decision trees are straightforward and interpretable models that are suitable for tasks involving categorical or discrete features, while neural networks are complex and powerful models that excel at capturing patterns and relationships in large datasets.
When comparing decision trees and neural networks, it is important to consider the advantages and limitations of each model.
A decision tree is a simple yet powerful algorithm used in machine learning for classification and regression tasks. It works by partitioning the training data based on different conditions until it reaches the desired outcome. Each condition forms a node in the tree, and the outcome is represented by the leaf nodes.
Decision trees have several advantages. They are easy to understand and interpret, as the resulting model can be visualized. They can handle both categorical and numerical data, and they can handle missing values. Decision trees can also handle non-linear relationships and interactions between variables.
The key differences between decision trees and neural networks lie in their structure and learning approach. Decision trees are composed of nodes and branches, while neural networks consist of interconnected neurons. Decision trees partition the data based on conditions, while neural networks learn to make predictions from the data using weights and biases. Decision trees are less prone to overfitting and can handle categorical data well, while neural networks excel in modeling complex patterns and relationships.

A decision tree is a good choice when the problem at hand is relatively simple and interpretable. If you have categorical or mixed data, or if you want a model that can be easily understood by non-technical stakeholders, a decision tree is a suitable option. Decision trees are also faster to train and evaluate compared to neural networks. However, if the problem requires modeling complex patterns or relationships, or if the data has a large number of features, a neural network may be a better choice.
Yes, decision trees can be used for regression tasks as well. In regression tasks, the outcome variable is continuous instead of categorical, and the decision tree algorithm adjusts the split points to minimize the variance of the outcome variable within each partition. The final outcome for a given input is then determined by the average value of the outcome variable in the corresponding leaf node.
Decision trees are models that use a tree-like structure to make decisions and create predictions based on input features. Neural networks, on the other hand, are a type of machine learning model inspired by the human brain. They consist of interconnected nodes (neurons) and are used for tasks such as classification, regression, and pattern recognition.
One key difference is the structure: decision trees are hierarchical, whereas neural networks have interconnected layers. Decision trees are easy to interpret and understand, while neural networks are often referred to as “black boxes” due to their complex inner workings. Additionally, decision trees can handle both categorical and numerical data, while neural networks typically require normalized numerical inputs. Decision trees perform well with small to medium-sized datasets, while neural networks excel with larger datasets.

How to Use ATR (Average True Range) In the world of financial trading, there are numerous technical indicators that traders use to analyze price …
Read Article
Best Leverage Options for $3000 Trading with leverage can be a powerful strategy for maximizing returns in the financial markets. By utilizing …
Read Article
Understanding the Parity of a Put-Call Option Options trading is a popular investment strategy that allows traders to profit from the price movements …
Read Article
How Does News Impact Forex Trading? Forex trading, also known as foreign exchange trading, is a popular investment option that allows individuals to …
Read Article
What are Aztec Codes? Aztec codes are a type of barcode that is becoming increasingly popular due to its ability to store large amounts of information …
Read Article
Is UniCredit a commercial bank? UniCredit is a leading European commercial bank with a strong presence in Italy and other key markets. With its …
Read Article



