


O padrão harmônico é de alta? Descubra o potencial dos padrões harmônicos de alta
Entendendo se os padrões harmônicos são de alta Os padrões harmônicos são uma técnica popular usada pelos traders para identificar possíveis reversões …
Leia o artigo

O SVM (Support Vector Machines, Máquinas de Vetores de Suporte) é um poderoso algoritmo de aprendizado de máquina amplamente utilizado para tarefas de classificação e regressão. Ele funciona encontrando um hiperplano ideal que separa os pontos de dados em diferentes classes. O SVM é conhecido por sua capacidade de lidar com dados de alta dimensão e por sua robustez em relação a outliers.
Uma das principais vantagens do SVM é sua flexibilidade. Ele pode ser usado para tarefas de classificação linear e não linear usando diferentes tipos de kernels. Os kernels mais comumente usados são linear, polinomial, função de base radial (RBF) e sigmoide. Cada kernel tem suas próprias características e pode ser escolhido com base no problema específico em questão.
O SVM é particularmente útil quando os dados não são linearmente separáveis. Ele pode lidar com limites de decisão complexos e é capaz de capturar relações não lineares entre os recursos e a variável-alvo. O SVM também é conhecido por sua capacidade de lidar com grandes conjuntos de dados de forma eficiente, pois depende apenas de um subconjunto de dados de treinamento chamado de vetores de suporte.
Outra vantagem do SVM é sua capacidade de lidar com dados de alta dimensão. Ele pode lidar de forma eficaz com um grande número de recursos sem se ajustar demais, ao contrário de outros algoritmos de aprendizado de máquina. Isso faz com que o SVM seja uma escolha popular em muitos campos, incluindo visão computacional, bioinformática e classificação de texto.
Em conclusão, as máquinas de vetores de suporte (SVM) são um algoritmo de aprendizado de máquina versátil que pode ser usado em uma ampla gama de aplicações. Não importa se você está trabalhando com dados lineares ou não lineares, o SVM oferece uma ferramenta poderosa para tarefas de classificação e regressão. Sua capacidade de lidar com dados de alta dimensão e sua robustez em relação a outliers fazem dele uma escolha popular entre cientistas de dados e profissionais de aprendizado de máquina.
O SVM (Support Vector Machines, Máquinas de Vetores de Suporte) é um poderoso algoritmo de aprendizado de máquina amplamente utilizado para problemas de classificação e regressão. O SVM é um algoritmo de aprendizado supervisionado que analisa os dados e encontra o melhor limite de decisão que separa as classes ou prevê a variável-alvo contínua.
A principal ideia por trás do SVM é encontrar o hiperplano em um espaço de dimensão superior que melhor separa os dados de treinamento em diferentes classes. Em termos simples, o SVM encontra a linha ou o hiperplano ideal que maximiza a margem entre as classes. Essa linha ou hiperplano ideal é escolhido de forma a separar ao máximo os pontos de dados de diferentes classes. O SVM pode lidar com dados linearmente separáveis e não linearmente separáveis usando diferentes funções de kernel.
Como o SVM funciona? Vejamos o caso da classificação binária. No SVM, cada ponto de dados é representado como um vetor de recurso em um espaço de dimensão superior com base em suas características. Em seguida, o algoritmo SVM mapeia esses dados em um espaço de dimensão superior, onde tenta encontrar um hiperplano ideal que separe as duas classes com a margem máxima.
A margem é definida como a distância perpendicular do hiperplano até os pontos de dados mais próximos de cada classe. O SVM busca maximizar essa margem, pois acredita que uma margem maior leva a uma melhor generalização e a um erro menor em dados não vistos.
Caso as classes não sejam perfeitamente separáveis, o SVM permite alguma classificação errônea introduzindo uma “margem suave”. A margem suave permite que alguns pontos de dados sejam classificados incorretamente e possibilita um modelo mais flexível e robusto. A penalidade por classificação incorreta é controlada pelo parâmetro de regularização, que ajuda a determinar o equilíbrio entre o tamanho da margem e o erro de classificação incorreta.
O SVM também pode lidar com dados não linearmente separáveis, graças ao truque do kernel. O truque do kernel permite que o SVM transforme os dados em um espaço de dimensão superior, onde eles se tornam linearmente separáveis. O SVM usa diferentes funções de kernel, como linear, polinomial, função de base radial (RBF) e sigmoide, para mapear os dados nesse espaço de dimensão superior.
Em conclusão, o SVM é um poderoso algoritmo de aprendizado de máquina que encontra o melhor limite de decisão para separar ou prever diferentes classes ou alvos de regressão. Ele funciona encontrando um hiperplano ideal em um espaço de dimensão superior que maximiza a margem entre as classes. O SVM pode lidar com dados linearmente separáveis e não-linearmente separáveis usando diferentes funções de kernel, o que o torna um algoritmo versátil para várias tarefas de classificação e regressão.
1. Problemas de classificação:
Os SVMs são comumente usados para problemas de classificação binária, em que o objetivo é separar os pontos de dados em duas classes distintas. Por exemplo, as SVMs podem ser usadas para classificar e-mails como spam ou não spam, prever se um cliente vai ou não se arrepender ou identificar se um paciente tem ou não uma doença.

2. Análise de texto e de sentimentos:
As SVMs são amplamente usadas em tarefas de processamento de linguagem natural. Elas podem ser usadas para análise de sentimentos, em que o objetivo é determinar o sentimento (positivo, negativo ou neutro) de um determinado texto ou avaliação. As SVMs também podem ser usadas para categorização de textos, classificação de documentos e agrupamento de textos.
3. Reconhecimento de imagens:
Os SVMs são eficazes em tarefas de reconhecimento de imagens, como detecção de objetos e reconhecimento de faces. Elas podem ser treinadas para classificar imagens em diferentes categorias, como identificar se uma imagem contém um carro ou uma pessoa. Os SVMs também têm sido usados no reconhecimento de expressões faciais e na segmentação de imagens.
Leia também: Contato com o Axis Bank Forex: Informações essenciais e detalhes de contato
4. Bioinformática:
Os SVMs encontraram várias aplicações em bioinformática, incluindo classificação de proteínas, análise de expressão gênica e análise de sequência de DNA. Os SVMs podem ser usados para prever a função de proteínas ou classificar genes com base em seus padrões de expressão, auxiliando na compreensão de processos biológicos e doenças.
5. Detecção de fraudes:
As SVMs podem ser usadas para a detecção de fraudes em vários domínios, como a detecção de fraudes em cartões de crédito ou em reclamações de seguros. Ao treinar um SVM em dados históricos de fraude, ele pode detectar padrões e anomalias em novos dados e sinalizar possíveis transações fraudulentas.
6. Reconhecimento de escrita à mão:
As SVMs têm sido usadas com sucesso no reconhecimento de escrita à mão, permitindo que as máquinas reconheçam e interpretem textos manuscritos. As SVMs podem ser treinadas em um conjunto de dados de caracteres manuscritos e, em seguida, usadas para classificar novas entradas manuscritas.
Leia também: O ADX é um bom indicador para escalpelamento? Aqui está o que você precisa saber
7. Sistemas de recomendação:
Os SVMs podem ser usados em sistemas de recomendação para sugerir produtos ou serviços relevantes aos usuários. Ao analisar o comportamento e as preferências do usuário, os SVMs podem prever as preferências do usuário e fornecer recomendações personalizadas.
8. Análise de séries temporais:
As SVMs têm sido utilizadas na análise de séries temporais para prever valores futuros ou detectar padrões em dados sequenciais. As SVMs podem ser aplicadas à previsão do mercado financeiro, previsão de preços de ações, previsão do tempo e outros conjuntos de dados dependentes do tempo.

9. Diagnóstico médico:
As SVMs podem auxiliar no diagnóstico médico analisando dados de pacientes, como sintomas, histórico médico e resultados de exames. Elas podem ser treinadas para classificar pacientes em diferentes categorias de doenças, auxiliar na previsão de resultados de doenças ou na identificação de possíveis fatores de risco.
10. Detecção de anomalias:
As SVMs podem ser usadas para detecção de anomalias em vários domínios, como detecção de intrusão na rede, detecção de fraudes ou detecção de falhas em equipamentos. Ao treinar um SVM em padrões de comportamento normais, ele pode identificar desvios ou outliers em novos dados, permitindo a detecção precoce de anomalias.
Em geral, as SVMs são versáteis e podem ser aplicadas a uma ampla gama de domínios e problemas. Sua capacidade de lidar com dados de alta dimensão, com relações não lineares e com tarefas de classificação binária e multiclasse faz com que sejam uma ferramenta valiosa em muitos aplicativos do mundo real.
Uma máquina de vetor de suporte (SVM) é um algoritmo de aprendizado de máquina supervisionado que pode ser usado tanto para tarefas de classificação quanto de regressão. Ele funciona encontrando o melhor hiperplano que separa os pontos de dados em diferentes classes.
As máquinas de vetor de suporte têm várias vantagens, incluindo a capacidade de lidar com dados de alta dimensão, a capacidade de lidar com dados lineares e não lineares e a capacidade de lidar com dados com um grande número de recursos. Elas também são menos propensas a ajustes excessivos em comparação com outros algoritmos.
Você deve considerar o uso de Support Vector Machines quando tiver um problema de classificação ou regressão e tiver um conjunto de dados relativamente pequeno com um número moderado de recursos. As SVMs também funcionam bem quando os dados são não linearmente separáveis ou quando há ruído nos dados.
Sim, as máquinas de vetor de suporte são sensíveis a outliers. Os outliers podem ter um impacto significativo sobre a posição e a orientação do hiperplano, o que pode levar a um desempenho ruim do algoritmo. O pré-processamento dos dados para remover os outliers ou o uso de versões robustas de SVMs pode ajudar a reduzir o impacto dos outliers.
As Support Vector Machines podem lidar com conjuntos de dados desequilibrados, mas podem não ter um bom desempenho se o desequilíbrio for grave. Nesses casos, técnicas como superamostragem da classe minoritária, subamostragem da classe majoritária ou uso de pesos de classe podem ser empregadas para melhorar o desempenho das SVMs.
Uma máquina de vetor de suporte (SVM) é um algoritmo de aprendizado de máquina supervisionado usado para tarefas de classificação e regressão. Ele funciona encontrando o melhor hiperplano possível em um espaço de recursos de alta dimensão para separar classes diferentes ou prever valores contínuos.
Há várias vantagens em usar máquinas de vetor de suporte (SVMs). Primeiro, as SVMs são eficazes em espaços de alta dimensão, o que as torna adequadas para problemas com um grande número de recursos. Em segundo lugar, as SVMs geralmente apresentam bom desempenho de generalização, o que significa que podem classificar com precisão dados não vistos. Por fim, as SVMs podem lidar com limites de decisão não lineares por meio do uso de funções de kernel.

Entendendo se os padrões harmônicos são de alta Os padrões harmônicos são uma técnica popular usada pelos traders para identificar possíveis reversões …
Leia o artigo
Como obter lucros consistentes com estratégias de Forex A negociação em Forex pode ser um empreendimento altamente lucrativo, mas também exige uma …
Leia o artigo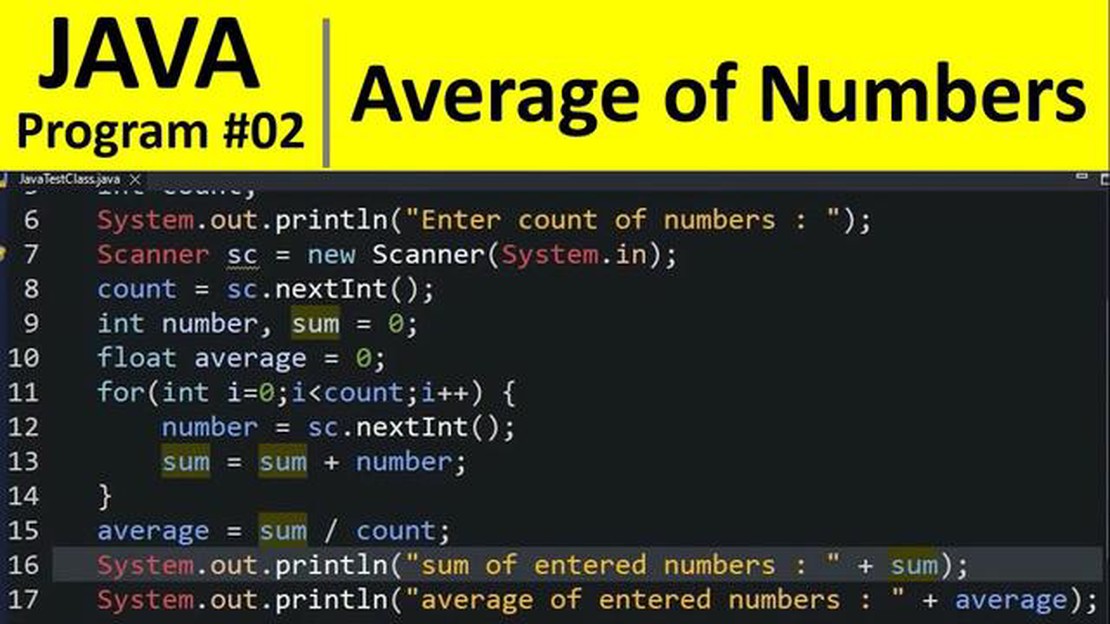
Como encontrar o código médio em Java Calcular o valor médio de um conjunto de números é uma tarefa comum em muitas linguagens de programação, …
Leia o artigo
A Bloomberg é uma boa plataforma para negociação em Forex? Quando se trata de plataformas de negociação forex, a confiabilidade é um fator crucial a …
Leia o artigo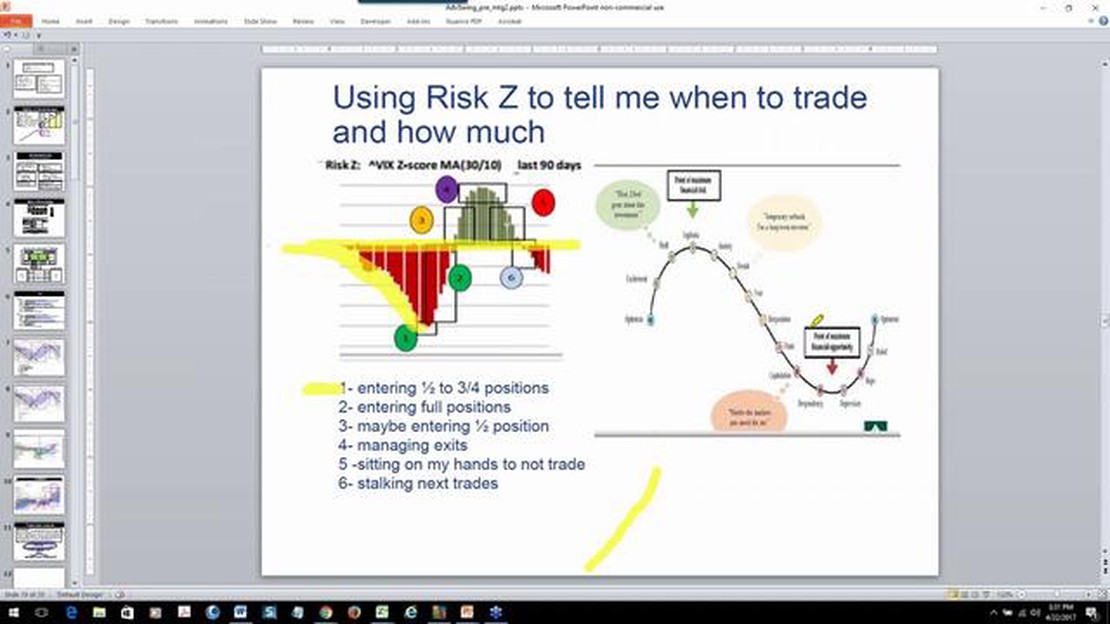
Qual é a pontuação Z para negociação de pares? A negociação de pares é uma estratégia de investimento popular que envolve a identificação e a …
Leia o artigo
O que significa IMC em negociação? IMC significa “International Market Centers”, que é uma operadora líder global de showrooms integrados e espaços de …
Leia o artigo



