


초보자 가이드: 파키스탄에서 트레이딩을 시작하는 방법?
파키스탄에서 거래하기: 단계별 가이드 파키스탄에서 거래하는 것은 추가 수입원을 창출하려는 개인들 사이에서 점점 인기를 얻고 있습니다. 초보자이든 거래 경험이 있든, 정보에 입각한 투자 결정을 내리려면 거래의 기본과 파키스탄 시장을 이해하는 것이 필수적입니다. 1단계: …
기사 읽기

시계열 분석 분야에서 ARIMA 모델은 데이터를 모델링하고 예측하는 데 널리 사용됩니다. ARIMA는 자동 회귀 통합 이동 평균의 약자로, 자동 회귀, 차분, 이동 평균의 개념을 결합하여 시계열 데이터의 복잡한 패턴을 포착합니다. 이 종합 가이드에서는 ARIMA 모델의 이동 평균 구성 요소에 특히 초점을 맞출 것입니다.
MA 모델이라고도 하는 이동 평균 모델은 ARIMA의 핵심 구성 요소입니다. 이 모델은 시계열 데이터에 존재하는 임의의 구성 요소 또는 노이즈를 포착하는 데 도움이 됩니다. MA 모델은 특정 시점의 시계열 값이 잔차라고도 하는 과거 오차 항의 선형 조합이라는 아이디어를 기반으로 합니다.
이동 평균 모델은 두 가지 주요 매개 변수, 즉 차분 순서(d)와 이동 평균 순서(q)로 정의됩니다. 차분 순서는 시계열을 고정 상태로 만들기 위해 차분해야 하는 횟수를 결정하고, 이동 평균 순서는 모델에 포함할 오차 항의 수를 결정합니다. 이러한 매개변수를 이해하고 올바르게 지정하면 정확하고 효과적인 MA 모델을 구축하여 시계열 데이터를 분석하고 예측할 수 있습니다.
이 가이드에서는 이동 평균 모델의 수학적 공식화, 매개변수의 해석, 모델 구축 및 평가 단계 등 이동 평균 모델의 개념에 대해 자세히 설명합니다. 또한 실제 시나리오에서의 적용을 설명하기 위해 실제 예제와 사례 연구에 대해서도 논의할 것입니다. 이 가이드가 끝나면 ARIMA의 이동 평균 모델을 포괄적으로 이해하고 자신의 시계열 데이터에 적용할 수 있는 지식을 갖추게 될 것입니다.
ARIMA의 맥락에서 이동평균(MA) 모델은 시계열 데이터를 분석하고 예측하는 데 도움이 되는 핵심 구성 요소입니다. 이 모델의 주요 초점은 이동 평균 프로세스에서 관측값과 잔차 오차 사이의 의존성에 있습니다.
MA 모델은 세 가지 주요 구성 요소로 이루어져 있습니다:
MA 모델은 다음과 같이 표현할 수 있습니다:

Xt = μ + εt + θ1εt-1 + θ2εt-2 + … + θqεt-q
또한 읽어보세요: MCX는 오늘 휴무인가요? | MCX 거래시간에 대한 최신 업데이트 및 일정
여기서 Xt는 t 시점의 시계열을 나타내고, μ는 상수, εt는 t 시점의 무작위 오차, θi는 MA 모델의 계수, q는 MA 모델의 순서를 나타냅니다.
MA 모델은 관측값과 잔차 오차 사이의 관계를 모델링하여 시계열의 단기 의존성 및 변동을 포착합니다. 시계열이 무작위적이거나 예측할 수 없는 행동을 보이는 경우에 특히 유용합니다.
MA 모델의 구성 요소를 분석하고 매개변수의 값을 추정함으로써 시계열의 기본 패턴과 추세에 대한 인사이트를 얻을 수 있습니다. 이를 통해 관찰된 데이터를 기반으로 정확한 예측과 예측을 할 수 있습니다.
이동 평균(MA) 모델은 자동 회귀 통합 이동 평균(ARIMA) 모델의 필수 구성 요소입니다. 이 모델은 시계열 데이터의 동작을 이해하고 예측하는 데 사용됩니다. 이 섹션에서는 ARIMA 프레임워크에서 이동 평균 모델을 적용하는 방법을 살펴보겠습니다.
ARIMA 모델에서 이동 평균 구성 요소는 데이터의 단기 변동을 포착하는 역할을 합니다. 이는 노이즈를 부드럽게 하고 기본 패턴이나 추세를 식별하는 데 도움이 됩니다. ARIMA에서 이동평균 모델을 적용하려면 모델의 적절한 순서를 선택하는 방법을 이해해야 합니다.
이동평균 모형의 순서는 MA(q)로 표시되며, 여기서 ‘q’는 모형에 포함할 후행 이동평균 항의 수를 나타냅니다. 후행 이동 평균 항은 과거 오차 항의 가중 평균입니다. 데이터의 단기 역학을 정확하게 포착하려면 “q"의 적절한 값을 선택하는 것이 중요합니다.
이동 평균 모델의 순서를 결정하는 방법에는 여러 가지가 있습니다. 한 가지 일반적인 접근 방식은 자동 상관 함수(ACF) 및 부분 자동 상관 함수(PACF) 플롯을 사용하는 것입니다. ACF 플롯은 이동 평균 구성 요소의 잠재적 순서를 식별하는 데 도움이 되며, PACF 플롯은 자동 회귀 구성 요소의 순서를 결정하는 데 도움이 됩니다.
또 다른 접근 방식은 Akaike 정보 기준(AIC) 및 베이지안 정보 기준(BIC)과 같은 정보 기준을 사용하는 것입니다. 이러한 기준은 모델 복잡성과 적합도 간의 균형을 제공하여 이동 평균 모델에 가장 적합한 순서를 선택할 수 있게 해줍니다.
또한 읽어보세요: 은행 환율 이해하기: GBP에서 EUR로 환전
이동 평균 모델의 순서를 결정한 후에는 최대 가능성 추정과 같은 기법을 사용하여 모델 매개 변수를 추정할 수 있습니다. 모델 파라미터를 추정하면 관찰된 데이터를 기반으로 예측을 하고 미래 값을 예측할 수 있습니다.

전반적으로 이동 평균 모델은 시계열 데이터를 분석하는 데 강력한 도구입니다. ARIMA 프레임워크 내에서 이를 적용하면 단기적인 역학을 정확하게 포착하고 의미 있는 예측을 할 수 있습니다. 신뢰할 수 있는 결과를 얻으려면 적절한 순서를 선택하고 모델 매개변수를 추정하는 방법을 이해하는 것이 중요합니다.
ARIMA의 이동 평균 모델은 시계열의 이전 값의 평균을 기반으로 시계열의 미래 값을 예측하는 데 사용되는 통계 기법입니다. 이동평균은 자동회귀 통합 이동평균을 의미하는 ARIMA 모델의 구성 요소입니다.
이동평균 모델은 이전 값 자체만 고려하는 것이 아니라 계열 내 이전 값의 평균을 고려한다는 점에서 자동회귀 모델과 같은 다른 모델과 다릅니다. 따라서 데이터의 불규칙성이나 변동을 완화하고 보다 정확한 예측을 제공하는 데 도움이 됩니다.
ARIMA에서 이동평균 모델을 사용하면 몇 가지 장점이 있습니다. 첫째, 데이터의 단기 변동을 제거하여 보다 안정적이고 정확한 예측을 제공하는 데 도움이 됩니다. 둘째, 이해하고 구현하기 비교적 간단한 모델입니다. 마지막으로, 시계열의 미래 값을 높은 수준의 정확도로 예측하는 데 사용할 수 있습니다.
예, ARIMA의 이동 평균 모델은 데이터에 어떤 형태의 추세 또는 계절성이 있는 한 모든 유형의 시계열 데이터에 사용할 수 있습니다. 그러나 이동 평균 모델이 모든 유형의 데이터에 적합하지 않을 수 있으며, 보다 정확한 예측을 제공하려면 자동 회귀 모델과 같은 다른 모델을 함께 사용해야 할 수 있다는 점에 유의하는 것이 중요합니다.

파키스탄에서 거래하기: 단계별 가이드 파키스탄에서 거래하는 것은 추가 수입원을 창출하려는 개인들 사이에서 점점 인기를 얻고 있습니다. 초보자이든 거래 경험이 있든, 정보에 입각한 투자 결정을 내리려면 거래의 기본과 파키스탄 시장을 이해하는 것이 필수적입니다. 1단계: …
기사 읽기
콜 옵션과 풋 옵션 이해하기: 단계별 가이드 콜옵션과 풋옵션에 대해 자세히 알고 싶으신가요? 이 종합 가이드는 인기 있는 금융 상품에 대해 자세히 알고 싶은 초보자를 위해 작성되었습니다. 야심찬 투자자이든 옵션이 어떻게 작동하는지 궁금한 초보자이든 이 가이드는 탄탄한 …
기사 읽기
태국에서 환율이 더 좋은가요? 해외 여행을 계획할 때 여행자가 자주 고려하는 요소 중 하나는 목적지 국가의 환율입니다. 아름다운 해변, 풍부한 문화, 맛있는 요리로 유명한 태국은 인기 있는 관광지입니다. 많은 여행자가 태국의 환율이 다른 나라보다 좋은지, 예산을 더 늘 …
기사 읽기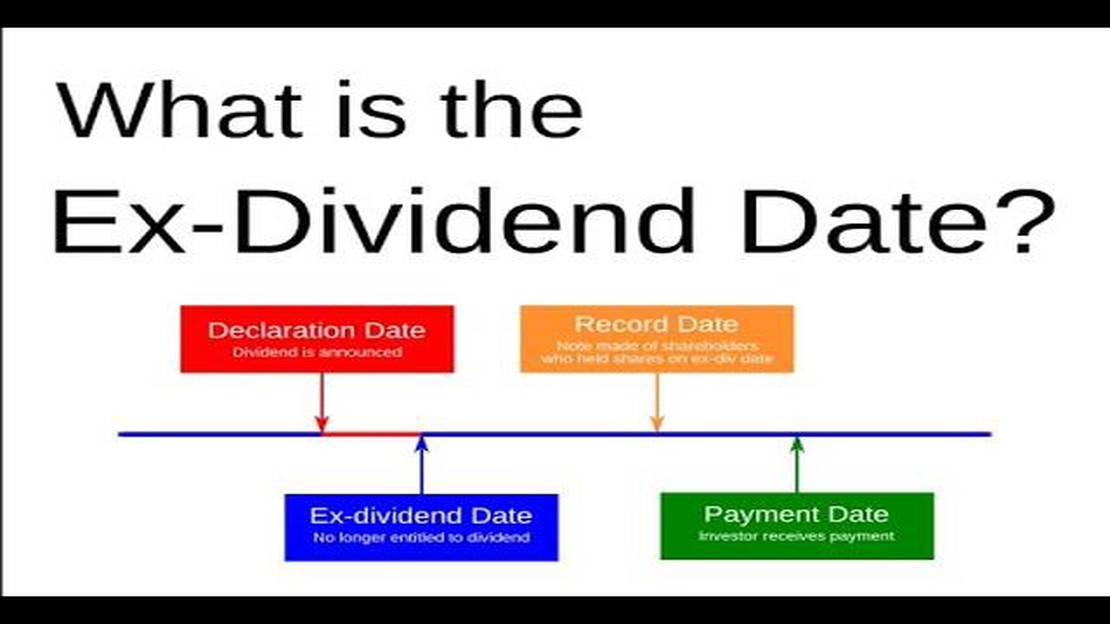
주식을 매도하기 가장 좋은 시기는 언제인가요? 배당금 전 또는 후? 주식에 투자할 때 고려해야 할 중요한 요소 중 하나는 배당금입니다. 배당금은 회사 수익 중 주주에게 분배되는 부분으로, 투자자에게 중요한 수입원이 될 수 있습니다. 그러나 배당금 지급일 전후에 주식을 …
기사 읽기
HSBC 거래 방법 트레이딩에 관심이 있고 새로운 기회를 모색하고 싶다면 HSBC가 완벽한 선택이 될 수 있습니다. 세계에서 가장 큰 은행 및 금융 서비스 기관 중 하나인 HSBC는 다양한 요구와 선호도에 맞는 다양한 거래 옵션을 제공합니다. 초보자이든 숙련된 트레이더 …
기사 읽기
1 유로에서 1 미국 달러 환율 유로와 미국 달러는 세계에서 가장 널리 사용되는 통화 중 하나입니다. 현재 기준] 유로와 미국 달러의 환율은 1유로 = 1미국 달러입니다. 즉, 1유로를 미국 달러 1달러로 교환할 수 있습니다. 목차 1유로에서 1미국 달러 환율 개요 1 …
기사 읽기


