


Pros y contras del trading automatizado: ¿Vale la pena?
¿Es beneficioso el trading automatizado? El trading automatizado, también conocido como trading algorítmico o algo trading, se ha hecho cada vez más …
Lee el artículo

Los valores atípicos son puntos de datos que se desvían significativamente de la media o de los patrones esperados dentro de un conjunto de datos. Estas anomalías pueden deberse a errores en la recogida de datos, imprecisiones en las mediciones o la presencia de sucesos poco frecuentes. Detectar y tratar los valores atípicos es crucial en el análisis de datos y puede afectar a la interpretación y validez de las conclusiones estadísticas.
Existen varias técnicas para identificar y tratar los valores atípicos, cada una con sus puntos fuertes y sus limitaciones. En este artículo se analizan cuatro métodos de uso común: el método de la puntuación z, el método del rango intercuartílico (IQR), el método del diagrama de caja y el método de la distancia de Mahalanobis.
El método de puntuación z consiste en calcular la puntuación estándar (puntuación z) de cada punto de datos, que mide cuántas desviaciones estándar se alejan de la media. Los puntos de datos con una puntuación z superior a un determinado umbral se consideran valores atípicos. Este método es sencillo y muy utilizado, pero asume una distribución normal y puede no funcionar bien con datos asimétricos.
El método IQR utiliza el rango intercuartílico, que es la diferencia entre el tercer cuartil (Q3) y el primer cuartil (Q1). Los puntos de datos por debajo de Q1 - 1,5 * IQR o por encima de Q3 + 1,5 * IQR se clasifican como valores atípicos. Este método es robusto a los valores atípicos y adecuado para datos sesgados, pero puede no ser eficaz para detectar valores atípicos en distribuciones multimodales o tamaños de muestra pequeños.
El método boxplot es un enfoque gráfico que proporciona una representación visual de la distribución de los datos. Los valores atípicos se identifican como puntos fuera de los bigotes del diagrama de caja, que suelen definirse como 1,5 veces la altura de la caja. Los gráficos de caja son útiles para comparar múltiples conjuntos de datos, pero pueden no ser tan sensibles a la hora de detectar valores atípicos en comparación con otros métodos.
El método de la distancia de Mahalanobis mide la distancia de cada punto de datos respecto al centroide del conjunto de datos, teniendo en cuenta la estructura de correlación entre las variables. Los puntos con una distancia de Mahalanobis superior a un determinado umbral se consideran valores atípicos. Este método es robusto a las correlaciones y tiene un buen rendimiento con datos multivariantes, pero requiere una muestra de gran tamaño y supone una distribución normal.
Comprender y aplicar estas técnicas de detección de valores atípicos puede ayudar a los investigadores y analistas de diversos campos a identificar y tratar eficazmente las anomalías, lo que conduce a resultados de análisis de datos más precisos y fiables.

En el análisis de datos, los valores atípicos se refieren a puntos de datos que se desvían significativamente del rango normal o de la tendencia de un conjunto de datos. Identificar y gestionar estas anomalías es crucial para obtener información precisa y tomar decisiones informadas. Afortunadamente, se han desarrollado varias técnicas para detectar y gestionar eficazmente los valores atípicos. En este artículo, exploraremos cuatro técnicas de uso común para la detección de valores atípicos.
El método de puntuación Z calcula la desviación estándar para medir cuántas desviaciones estándar se aleja un punto de datos de la media. Generalmente, una puntuación Z superior a un determinado umbral (a menudo 2 ó 3) puede considerarse un valor atípico. Este método es útil cuando el conjunto de datos sigue una distribución normal.
El método de las cercas de Tukey utiliza el rango intercuartílico (IQR) para identificar valores atípicos. El IQR es el rango entre el primer cuartil (Q1) y el tercer cuartil (Q3) del conjunto de datos. Cualquier punto de datos que caiga por debajo de Q1 - (1,5 * IQR) o por encima de Q3 + (1,5 * IQR) se considera un valor atípico. Este método es robusto frente a conjuntos de datos sesgados o no normales.
La distancia de Mahalanobis calcula la distancia entre un punto de datos y el centroide del conjunto de datos, teniendo en cuenta la covarianza de las variables. Una observación con una distancia de Mahalanobis elevada puede considerarse un valor atípico. Este método es útil para conjuntos de datos con múltiples variables o dimensiones.
Leer también: ¿Es Heikin-Ashi una opción adecuada para operar con opciones?
El algoritmo Isolation Forest es una técnica basada en el aprendizaje automático para la detección de valores atípicos. Construye árboles de aislamiento particionando recursivamente el conjunto de datos, aislando las anomalías en caminos más cortos en comparación con los puntos de datos normales. A continuación, las anomalías se identifican en función del número de particiones necesarias para aislarlas. Este método es eficaz y escalable para manejar grandes conjuntos de datos.
Una vez detectados los valores atípicos, pueden gestionarse mediante diversos enfoques. Algunas estrategias habituales son
En general, la detección precisa y la gestión adecuada de los valores atípicos son esenciales para mantener la integridad de los datos y mejorar la calidad de los análisis y las decisiones. Mediante el empleo de las técnicas y estrategias comentadas en este artículo, los analistas e investigadores pueden gestionar eficazmente los valores atípicos y extraer información significativa de sus conjuntos de datos.
Leer también: Las desventajas de los futuros sobre oro: Entender las desventajas
Los métodos estadísticos proporcionan un potente conjunto de herramientas para identificar y tratar los valores atípicos. Al aprovechar los patrones y distribuciones inherentes a los datos, estos métodos pueden ayudar a los investigadores y analistas a detectar y tratar anomalías que pueden afectar significativamente a la validez y fiabilidad de sus resultados.
Un método estadístico comúnmente utilizado para la detección de valores atípicos es la puntuación z. Este método calcula el número de desviaciones estándar que un punto de datos se desvía de la media de una distribución. Fijando un umbral, los investigadores pueden identificar los puntos de datos que quedan fuera de un rango definido y se consideran valores atípicos estadísticamente significativos.
Otro método estadístico es la puntuación z modificada, que aborda las limitaciones del método de puntuación z tradicional. La puntuación z modificada tiene en cuenta la mediana y la desviación absoluta de la mediana (MAD) en lugar de la media y la desviación estándar. Este enfoque estadístico robusto es menos sensible a los valores extremos y puede proporcionar una detección más precisa de valores atípicos en conjuntos de datos con distribuciones no normales o sesgadas.
Los métodos estadísticos también incluyen el uso de técnicas basadas en percentiles. Estos métodos consisten en establecer un umbral basado en un valor percentil, como el percentil 1 o el percentil 99. Los puntos de datos que caen por debajo o por encima de este umbral se definen como percentiles. Los puntos de datos que caen por debajo o por encima del umbral definido se consideran valores atípicos. Las técnicas basadas en el percentil son especialmente útiles cuando se trata de datos que siguen una distribución sesgada o tienen valores atípicos significativos en las colas de la distribución.

Además, métodos estadísticos como las cercas de Tukey y la prueba de Grubbs ofrecen procedimientos robustos para detectar valores atípicos. Las cercas de Tukey utilizan cuartiles para definir las cercas interiores y exteriores, lo que permite identificar valores atípicos basándose en los rangos intercuartílicos. Por otro lado, la prueba de Grubbs es una prueba de hipótesis que determina si un punto de datos se desvía significativamente de la media. Este método es útil para detectar valores atípicos en conjuntos de datos distribuidos normalmente.
En conclusión, los métodos estadísticos proporcionan herramientas valiosas para detectar valores atípicos aprovechando el poder de los números. Al comprender los patrones y distribuciones subyacentes en los datos, los investigadores y analistas pueden emplear estos métodos para identificar y tratar los valores atípicos que pueden afectar a la precisión y fiabilidad de sus análisis.
Los valores atípicos son puntos de datos que difieren significativamente de otros puntos de datos de un conjunto de datos. Es importante detectarlos porque pueden tener un impacto significativo en los análisis estadísticos y en los modelos de aprendizaje automático. Los valores atípicos pueden distorsionar los resultados y llevar a conclusiones inexactas. Por lo tanto, es importante identificar y tratar adecuadamente los valores atípicos para obtener resultados fiables y significativos.
Puede haber varias causas comunes de valores atípicos en los datos. Algunas de ellas son los errores de medición, los errores de introducción de datos, los errores de procesamiento de datos o las variaciones naturales de los datos. Los valores atípicos también pueden deberse a sucesos raros o extremos que se desvían del comportamiento normal del sistema estudiado. Es importante tener en cuenta estas posibles causas al analizar e interpretar los valores atípicos de un conjunto de datos.
Las cuatro técnicas de detección de valores atípicos son: 1) Métodos basados en estadísticas, como la puntuación z y la puntuación z modificada, que identifican valores atípicos basándose en las propiedades estadísticas de los datos; 2) Métodos basados en distancias, como k-vecinos más próximos y el factor local de valores atípicos, que miden la distancia o la densidad de los puntos de datos para identificar valores atípicos; 3) Métodos basados en modelos, como la regresión lineal y la agrupación, que utilizan modelos estadísticos para identificar puntos de datos que se desvían del patrón esperado; 4) Métodos de conjunto, que combinan múltiples técnicas de detección de valores atípicos para mejorar la precisión y la solidez.
Por supuesto. La detección de valores atípicos puede aplicarse en varios escenarios de la vida real. Por ejemplo, en las finanzas, la detección de valores atípicos puede ayudar a identificar transacciones fraudulentas o patrones inusuales en los datos financieros. En sanidad, la detección de valores atípicos puede utilizarse para identificar a pacientes con lecturas médicas o síntomas anómalos. En la industria manufacturera, la detección de valores atípicos puede ayudar a identificar productos defectuosos o desviaciones de los procesos de producción normales. Estos son sólo algunos ejemplos de cómo puede utilizarse la detección de valores atípicos para mejorar la toma de decisiones y la resolución de problemas en distintos sectores.

¿Es beneficioso el trading automatizado? El trading automatizado, también conocido como trading algorítmico o algo trading, se ha hecho cada vez más …
Lee el artículo
Tipo de venta en el mercado abierto de 1 dólar por PKR El tipo de cambio de venta en el mercado abierto (Open Market Selling Rate, OMSR) es el tipo de …
Lee el artículo
Domine Forex en sólo 6 meses: La Guía Definitiva El mercado de divisas, también conocido como comercio de divisas, se ha hecho cada vez más popular en …
Lee el artículo
Comprender el nivel de apalancamiento en IG MT4 Apalancamiento es un término comúnmente utilizado en el comercio financiero que se refiere a la …
Lee el artículo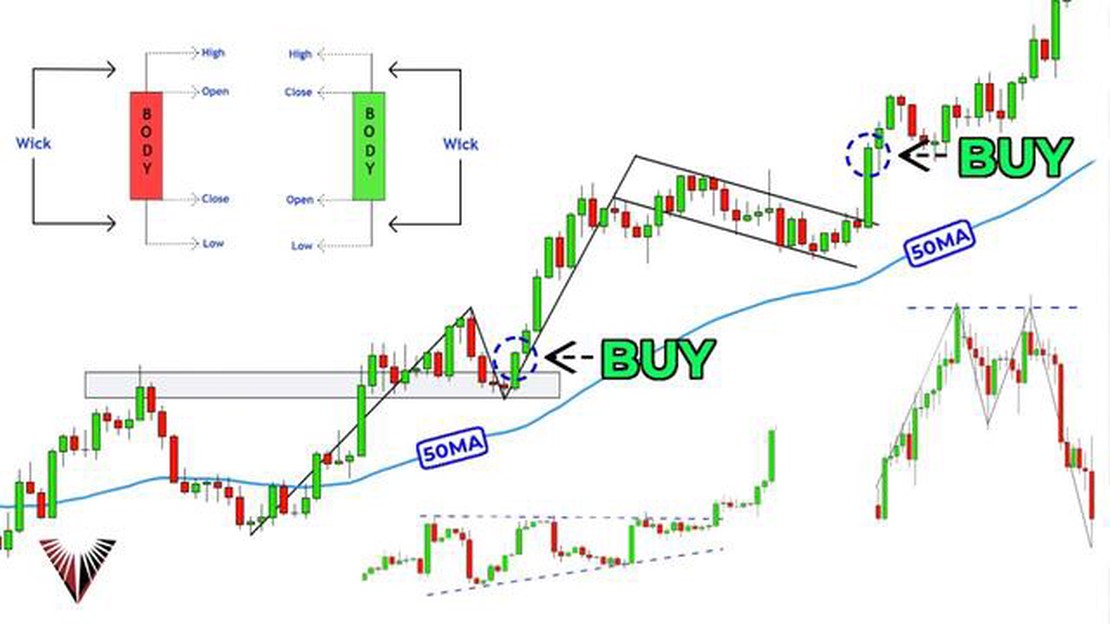
El mejor análisis técnico para operar A la hora de operar en los mercados financieros, es fundamental contar con una estrategia sólida de análisis …
Lee el artículo
Operar con acciones con el Nivel 2: Guía completa Operar con acciones puede ser una tarea compleja y difícil, pero comprender y utilizar los datos de …
Lee el artículo



